Автор: Денис Аветисян
Новое исследование показывает, как обогащение данных обучения информацией о метаданных может значительно повысить скорость и качество освоения языковых моделей.

Исследование посвящено влиянию разнообразия и позиционирования метаданных, а также использованию обучаемых мета-токенов для повышения эффективности предварительного обучения больших языковых моделей.
Несмотря на успехи больших языковых моделей, предварительное обучение остается ресурсоемкой задачей, требующей оптимизации. В работе ‘Beyond URLs: Metadata Diversity and Position for Efficient LLM Pretraining’ исследуется влияние разнообразных метаданных на эффективность предварительного обучения, выходя за рамки использования только URL-адресов. Показано, что использование более детальных показателей качества документов и применение методов добавления метаданных, а также обучаемые мета-токены, позволяют ускорить процесс обучения и улучшить структуру латентных представлений. Какие еще скрытые возможности несут в себе метаданные для повышения эффективности и результативности предварительного обучения больших языковых моделей?
Основы: Предварительное обучение языковых моделей и качество данных
Современные большие языковые модели (БЯМ) демонстрируют впечатляющие возможности, во многом благодаря обучению на колоссальных объемах данных. Однако, простое увеличение масштаба обучающего корпуса не гарантирует качественного результата. Исследования показывают, что производительность модели зависит не только от количества информации, но и от её релевантности и структуры. Несмотря на кажущуюся очевидность, часто наблюдается тенденция к накоплению огромных, но не всегда полезных массивов данных, что приводит к замедлению обучения, увеличению вычислительных затрат и, как следствие, к снижению общей эффективности модели. Таким образом, фокус смещается от простого масштабирования к более продуманному подходу, включающему в себя тщательный отбор и фильтрацию данных, что становится ключевым фактором для достижения устойчивой и надежной работы БЯМ.
Качество данных, используемых для предварительного обучения больших языковых моделей, имеет первостепенное значение. Несоответствующий или низкокачественный контент способен существенно затруднить процесс обучения и привести к формированию предвзятости в модели. Это происходит из-за того, что языковая модель, подобно губке, впитывает информацию из обучающих данных, и если эта информация нерелевантна, содержит ошибки или отражает определенные предубеждения, модель будет воспроизводить и усиливать эти недостатки. Таким образом, тщательный отбор и очистка данных являются критически важными для обеспечения надежности, точности и справедливости создаваемых языковых моделей, что, в свою очередь, определяет их способность к эффективному и безопасному применению в различных областях.
Эффективная фильтрация данных играет ключевую роль в обучении больших языковых моделей, позволяя существенно повысить их производительность и минимизировать риски генерации вредоносного или предвзятого контента. Исследования показывают, что тщательно отобранные и очищенные наборы данных не только улучшают качество ответов модели, но и позволяют сократить необходимое количество обучающих токенов на 30-40% по сравнению со стандартными подходами к предобучению. Это достигается за счет исключения нерелевантной, низкокачественной или дублирующейся информации, что позволяет модели более эффективно усваивать полезные знания и фокусироваться на действительно значимых паттернах в языке. Таким образом, инвестиции в разработку и применение передовых методов фильтрации данных являются критически важными для создания надежных и эффективных языковых моделей.

Метаданные как ключ: Обогащение языковых моделей контекстом
Традиционное предварительное обучение больших языковых моделей (LLM) часто не учитывает метаданные документов, такие как источники, даты публикации или авторы. Это приводит к потере контекстуальной информации, необходимой для более точной интерпретации и генерации текста. Отсутствие доступа к этим данным ограничивает способность модели понимать нюансы, связанные с происхождением информации, и может приводить к неточностям или нерелевантным ответам. Игнорирование метаданных особенно критично в сценариях, где важна достоверность и актуальность информации, поскольку модель не имеет возможности оценить надежность источника или временной контекст.
Метаданные, такие как источник документа, дата публикации или автор, часто игнорируются в процессе предварительного обучения больших языковых моделей (LLM). Метаобусловленность предоставляет механизм для включения этой информации в обучающий корпус, что позволяет модели учитывать контекст создания текста. Внедрение метаданных позволяет улучшить осведомленность модели о происхождении данных и, как следствие, повысить точность и релевантность генерируемых ответов. Данный подход особенно важен для задач, где знание контекста документа критически важно, например, при работе с новостными статьями, юридическими документами или научными публикациями.
Существуют два основных метода внедрения метаданных в корпус предварительного обучения языковых моделей: добавление URL в начало текста (URL Prepending) и добавление метаданных в конец текста (Metadata Appending). Метод URL Prepending предполагает конкатенацию URL-адреса источника документа с началом текста, что позволяет модели ассоциировать контент с конкретным веб-сайтом. Metadata Appending, напротив, добавляет структурированные метаданные, такие как автор, дата публикации или категория, в конец текста. Выбор метода зависит от специфики данных и задачи; URL Prepending может быть полезен для задач, связанных с источником информации, в то время как Metadata Appending обеспечивает более явное представление о характеристиках самого контента.
Использование детализированных метаданных позволяет достичь сопоставимой производительности с базовой моделью, обученной на 100 миллиардах токенов, используя лишь 60 миллиардов токенов, что представляет собой сокращение примерно на 40%. Дальнейшее усовершенствование достигается за счет применения обучаемых мета-токенов (Learnable Meta Tokens), которые позволяют модели динамически изучать оптимальное представление метаданных, что повышает эффективность обучения и улучшает общую производительность.

Внутреннее устройство: Послойный анализ репрезентаций
Простое добавление метаданных к обучающим данным недостаточно для эффективного использования этой информации моделью. Необходимо анализировать, как модель обрабатывает и интегрирует эти данные в свои внутренние представления. Модель может игнорировать предоставленные метаданные, либо использовать их неэффективно, если не понимать механизм их обработки на различных уровнях её архитектуры. Исследование процессов обработки метаданных позволяет выявить, какие слои модели наиболее чувствительны к конкретным типам метаданных, и как эти данные влияют на формирование внутренних представлений и, в конечном итоге, на качество предсказаний. Понимание этого механизма критически важно для оптимизации интеграции метаданных и повышения интерпретируемости модели.
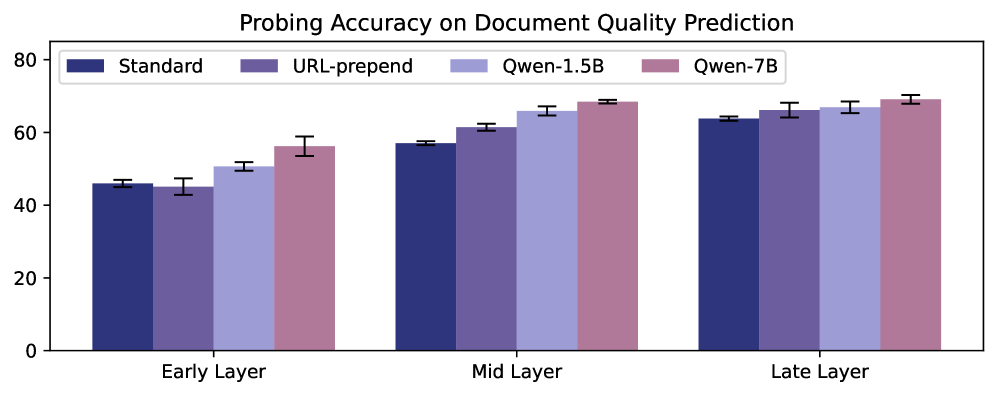
Метод послойного зондирования (Layer-wise Probing) позволяет анализировать внутренние представления, формируемые различными слоями модели, с целью выявления влияния метаданных на процесс обучения. Данный подход предполагает извлечение векторов активации из каждого слоя модели при обработке входных данных, и последующий анализ этих векторов с использованием различных методов машинного обучения, таких как классификация или кластеризация. Анализ позволяет определить, какие слои модели наиболее чувствительны к изменениям в метаданных, и как именно метаданные изменяют структуру и организацию представлений, формируемых моделью. В частности, можно оценить, как метаданные влияют на способность модели различать различные классы документов или предсказывать их качество.
Анализ внутренних представлений модели, полученных методом layer-wise probing, позволяет выявить структуру и организацию этих представлений — так называемую «геометрию представлений». Результаты probing демонстрируют, что использование URL и детальных оценок качества документа в качестве условий для модели приводит к повышению точности предсказания качества документа. В частности, наблюдается улучшение способности модели различать документы различного качества и более точно оценивать их соответствие заданным критериям, что подтверждается количественными показателями точности предсказания.
Анализ внутренних представлений модели посредством зондирования слоёв предоставляет данные, позволяющие оптимизировать стратегии интеграции метаданных и повысить интерпретируемость модели. Результаты зондирования выявляют, какие слои и каким образом используют предоставленные метаданные, такие как URL и оценки качества, для формирования представлений о документах. Это позволяет определить, какие типы метаданных наиболее эффективно влияют на конкретные аспекты обучения модели, и, следовательно, более целенаправленно внедрять и взвешивать метаданные в процессе обучения. На основе этих данных можно разрабатывать методы улучшения архитектуры модели или алгоритмов обучения, что в итоге повысит точность предсказаний и обеспечит более глубокое понимание процессов, происходящих внутри модели.
Эффективность и масштаб: Разреженные смеси экспертов
Традиционно, повышение производительности языковых моделей достигалось за счет увеличения их размера — количества параметров. Однако, эта стратегия сопряжена со значительными вычислительными издержками. С ростом числа параметров экспоненциально возрастают требования к памяти и вычислительной мощности, что делает обучение и развертывание крупных моделей чрезвычайно дорогими и ресурсоемкими. Например, обучение модели с миллиардами параметров требует огромных кластеров графических процессоров и значительного времени, что ограничивает доступность таких моделей для широкого круга исследователей и разработчиков. В результате, возникает необходимость в альтернативных подходах, позволяющих улучшить производительность моделей без пропорционального увеличения вычислительных затрат, что и стимулирует поиск более эффективных архитектур и методов обучения.
Архитектура разреженных смесей экспертов (Sparse Mixture-of-Experts) представляет собой инновационный подход к масштабированию языковых моделей, позволяющий значительно снизить вычислительные затраты. В отличие от традиционных моделей, где для обработки каждого запроса активируются все параметры, данная архитектура задействует лишь небольшое подмножество, выбранное в зависимости от конкретного входного сигнала. Это достигается за счет разделения модели на множество «экспертов», каждый из которых специализируется на определенной части пространства входных данных. Механизм маршрутизации определяет, какие эксперты наиболее подходят для обработки текущего запроса, активируя их и отключая остальные. Такой подход позволяет значительно увеличить емкость модели без пропорционального увеличения вычислительной нагрузки, открывая возможности для создания более мощных и эффективных языковых моделей.
Архитектура разреженных смесей экспертов (Sparse Mixture-of-Experts) демонстрирует значительный потенциал при интеграции с методами метаданных-обусловливания, позволяя создавать крайне эффективные и хорошо осведомленные большие языковые модели. Внедрение метаданных, описывающих контекст или характеристики входных данных, позволяет модели динамически выбирать наиболее релевантных экспертов для обработки конкретного запроса. Это не только снижает вычислительные затраты, поскольку активируется лишь часть параметров, но и значительно повышает качество ответов, поскольку модель может адаптироваться к различным типам информации и задачам. В результате, достигается оптимальный баланс между производительностью, эффективностью и объемом знаний, что открывает новые возможности для создания интеллектуальных систем обработки естественного языка.
В процессе обучения больших языковых моделей, предварительное добавление URL-адресов к входным данным может спровоцировать феномен, известный как «Attention Sink». Этот эффект заключается в том, что механизм внимания модели начинает чрезмерно фокусироваться на добавленных URL, игнорируя при этом значимую информацию из основного текста. В результате, производительность модели может значительно снизиться, так как она неверно интерпретирует входные данные. Для предотвращения «Attention Sink» необходимо тщательно контролировать процесс обучения, применяя регуляризацию и другие методы, направленные на балансировку внимания между различными частями входной последовательности и обеспечение корректной обработки информации из всех источников. Особое внимание следует уделять настройке гиперпараметров и выбору оптимальной стратегии обучения, чтобы избежать чрезмерной зависимости механизма внимания от добавленных URL.

Исследование демонстрирует, что эффективное предварительное обучение больших языковых моделей требует не только объёма данных, но и их структурированной организации. Авторы статьи справедливо подчеркивают важность метаданных и способов их интеграции в процесс обучения. Этот подход перекликается с математической элегантностью, поскольку позволяет алгоритму более эффективно использовать информацию, сокращая время обучения и улучшая качество представлений. В этом контексте, замечание Блеза Паскаля: «Все великие дела требуют времени», обретает новый смысл. Действительно, оптимизация процесса обучения за счёт использования метаданных — это инвестиция времени, приводящая к существенным улучшениям в производительности модели. Применение learnable meta tokens, как показано в исследовании, является ярким примером такого подхода, позволяя модели динамически адаптироваться к различным типам данных и, следовательно, достигать более высокой точности.
Куда Дальше?
Представленные результаты, несомненно, демонстрируют потенциал метаданных для управления процессом обучения больших языковых моделей. Однако, не стоит обманываться кажущейся эффективностью. Улучшение скорости обучения — это лишь следствие, а не причина. Гораздо важнее понять, действительно ли добавление метаданных формирует более корректные представления, или же мы просто наблюдаем искусную оптимизацию, маскирующую фундаментальные недостатки в архитектуре и методах обучения. Эвристика «добавить больше данных» всегда заманчива, но истинная элегантность — в минимализме, в доказательстве сходимости, а не в эмпирических наблюдениях.
Очевидным направлением для дальнейших исследований является формализация понятия “гранулярности” метаданных. Что значит “достаточно гранулярные” метаданные? Существует ли предел, после которого добавление новых деталей становится контрпродуктивным, увеличивая сложность модели без улучшения ее способности к обобщению? Необходимо разработать метрики, позволяющие объективно оценивать влияние метаданных на качество получаемых представлений, а не только на скорость обучения. И, конечно, следует задуматься о связи между метаданными и способностью модели к логическому выводу, а не только к статистическому сопоставлению.
Использование обучаемых мета-токенов — многообещающий шаг, но и здесь кроется опасность. Не превратится ли это в еще один способ “закодировать” информацию в параметрах модели, вместо того чтобы научить ее самостоятельно извлекать знания из данных? Истинная интеллектуальная система должна быть способна к дедукции, а не к запоминанию. В конечном счете, задача состоит не в том, чтобы сделать модели “быстрее”, а в том, чтобы сделать их умнее.
Оригинал статьи: https://arxiv.org/pdf/2511.21613.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые нейросети на службе нефтегазовых месторождений
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Квантовый Переход: Пора Заботиться о Криптографии
- Квантовая обработка данных: новый подход к повышению точности моделей
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Лунный гелий-3: Охлаждение квантового будущего
- Квантовые сети для моделирования молекул: новый подход
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Квантовые прорывы: Хорошее, плохое и смешное
2025-11-30 22:05