Автор: Денис Аветисян
В статье представлен всесторонний обзор современных аппаратных решений для ускорения нейронных сетей, охватывающий ключевые проблемы и перспективные направления развития.
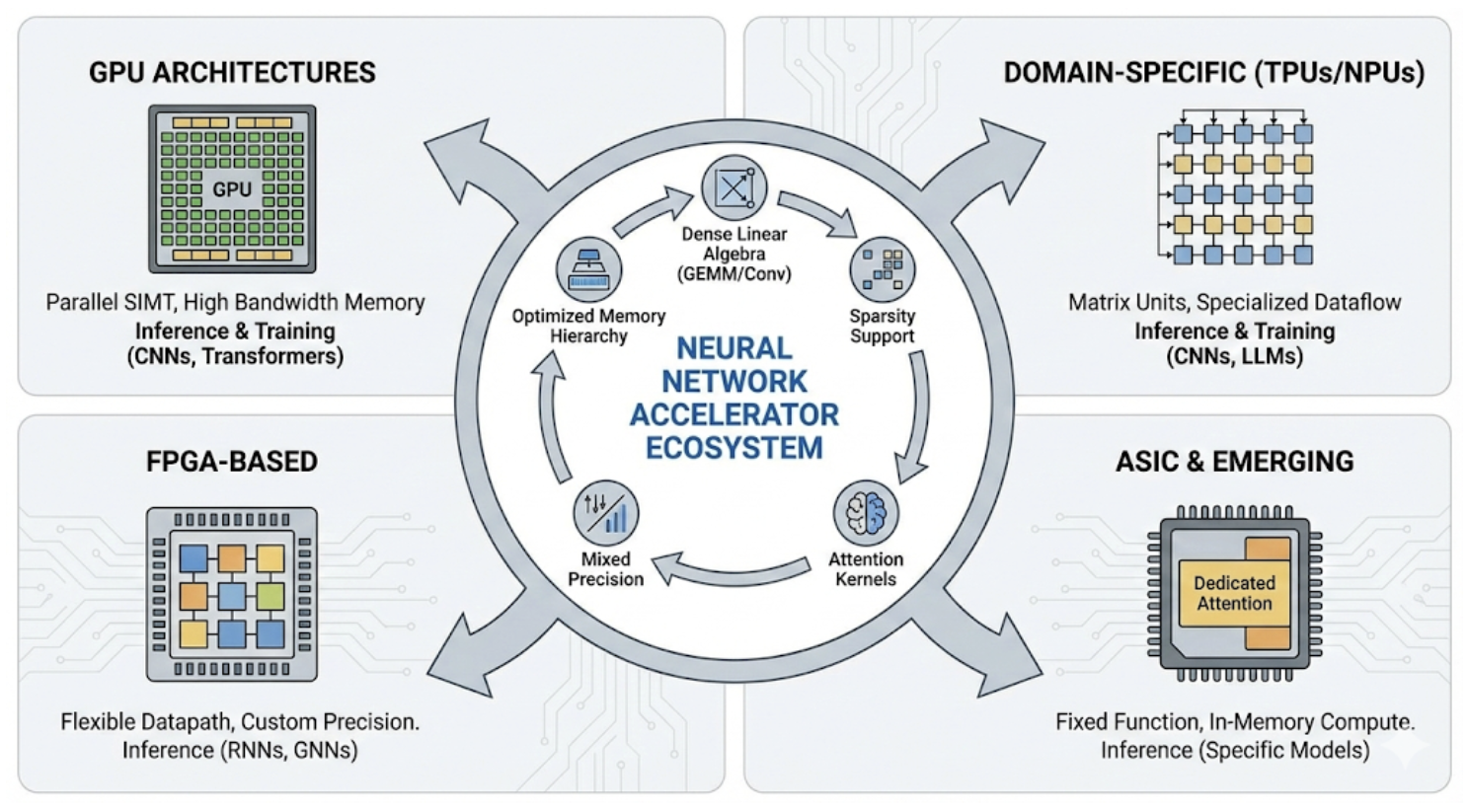
Обзор архитектур, оптимизаций и тенденций в области аппаратного ускорения нейронных сетей, включая энергоэффективность, разреженные вычисления и вычисления в памяти.
Несмотря на стремительное развитие нейронных сетей, их широкое применение сдерживается аппаратными ограничениями, особенно в части пропускной способности памяти и энергоэффективности. Настоящий обзор, ‘Hardware Acceleration for Neural Networks: A Comprehensive Survey’, систематизирует ландшафт аппаратных ускорителей глубокого обучения, охватывая от GPU и тензорных процессоров до специализированных ASIC и перспективных подходов вроде вычислений в памяти. Ключевой вывод исследования заключается в том, что эффективное ускорение требует комплексной оптимизации архитектуры, алгоритмов и программного обеспечения с учетом разнообразия рабочих нагрузок и условий развертывания. Какие инновации в области аппаратного обеспечения и компиляции позволят реализовать потенциал будущих поколений нейронных сетей, особенно в задачах обработки больших языковых моделей?
Суть Проблемы: Пределы Памяти и Вычислений
Современные нейронные сети, особенно архитектура Transformer, демонстрируют экспоненциальный рост потребностей в вычислительных ресурсах. Этот феномен обусловлен увеличением размеров моделей и объемов обрабатываемых данных, необходимых для достижения высокой точности в сложных задачах, таких как обработка естественного языка и компьютерное зрение. Каждый новый прорыв в области искусственного интеллекта требует значительно больше операций с плавающей точкой и объема памяти, что создает серьезные проблемы для масштабируемости и энергоэффективности. Стремительное увеличение параметров моделей, таких как GPT-3 и подобные, приводит к тому, что обучение и даже применение этих сетей становится непосильной задачей для стандартного оборудования, требуя специализированных ускорителей и инновационных подходов к вычислениям.
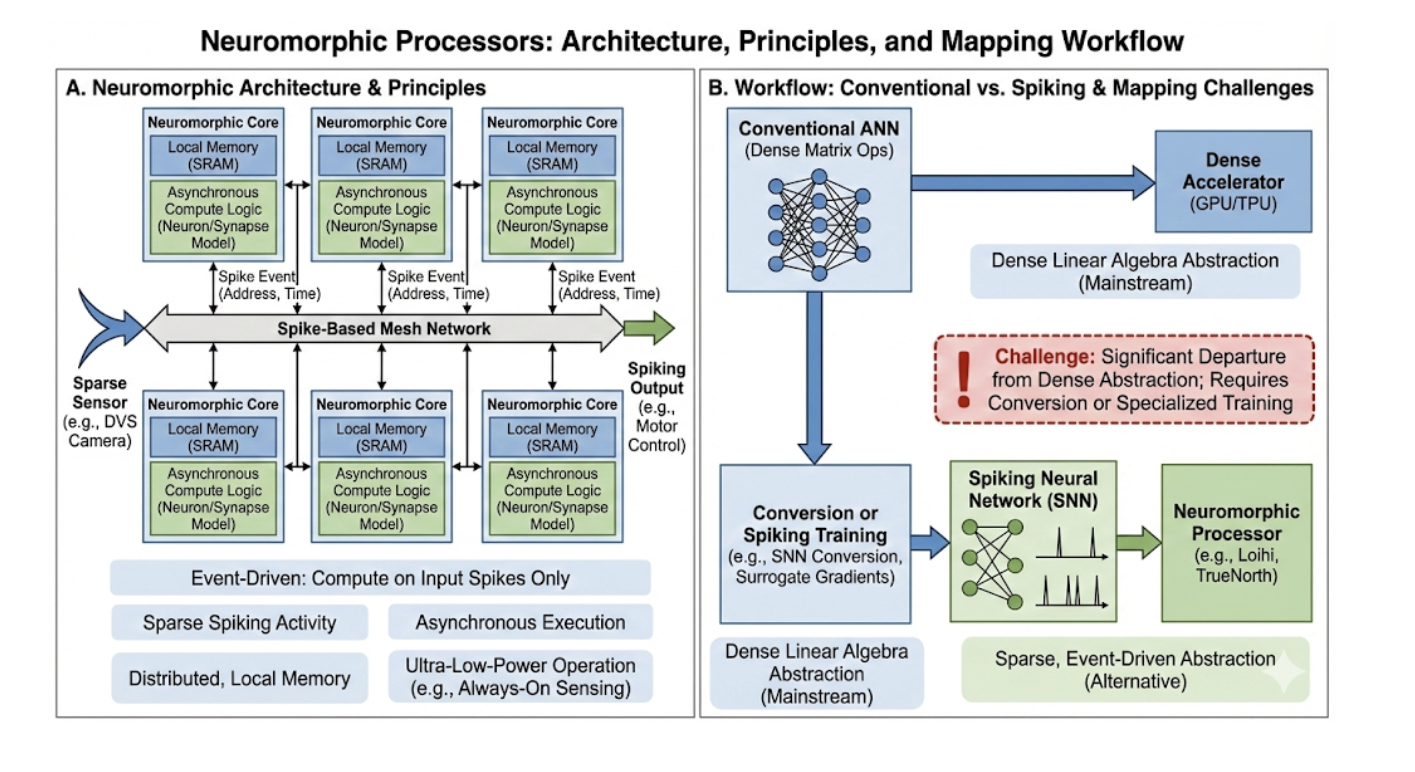
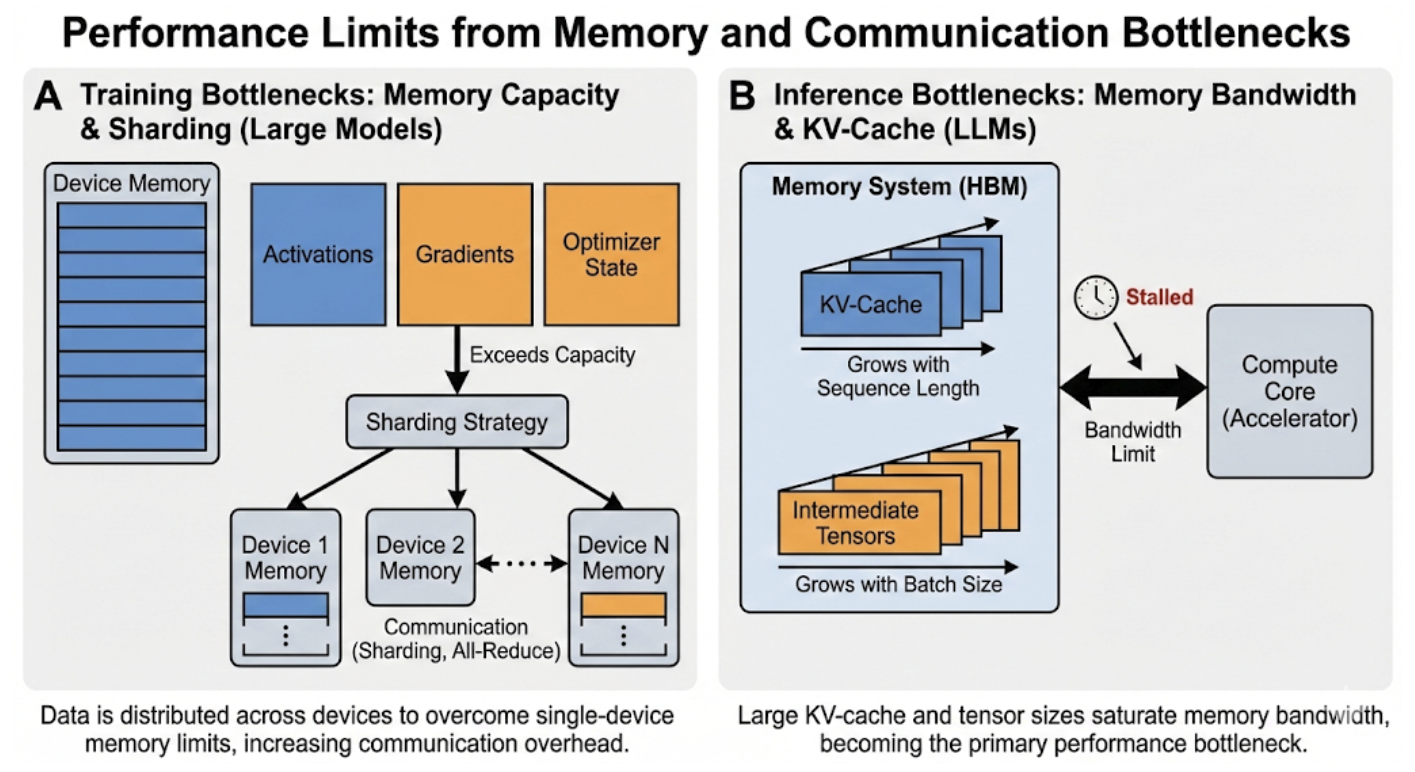
Традиционные архитектуры фон Неймана, лежащие в основе большинства современных вычислительных систем, испытывают серьезные трудности при работе с постоянно растущими потребностями нейронных сетей. Основная проблема заключается в раздельном размещении процессора и памяти, что приводит к необходимости постоянного перемещения данных между ними. Этот процесс, известный как «узкое место памяти», существенно ограничивает скорость обработки информации и требует значительных энергозатрат. По мере увеличения размера нейронных сетей и сложности решаемых задач, количество необходимых перемещений данных растет экспоненциально, что делает дальнейшее масштабирование вычислительных мощностей все более проблематичным и неэффективным. Поэтому, для преодоления данного ограничения, активно разрабатываются новые подходы к архитектуре вычислительных систем, такие как нейроморфные вычисления и вычисления в памяти, которые стремятся к более тесной интеграции процессора и памяти, минимизируя необходимость перемещения данных и повышая энергоэффективность.
Существующее ограничение пропускной способности памяти оказывает всё более заметное влияние на развитие современных нейронных сетей, замедляя как процесс обучения, так и последующее применение обученных моделей. Особенно остро эта проблема проявляется в устройствах с ограниченными ресурсами, таких как мобильные телефоны или встраиваемые системы, где вычислительные мощности и объём доступной памяти строго ограничены. Невозможность эффективно обрабатывать растущие объёмы данных приводит к увеличению времени обработки, снижению точности и, в конечном итоге, препятствует внедрению передовых технологий искусственного интеллекта в повседневную жизнь. Поэтому поиск решений, позволяющих оптимизировать использование памяти и снизить вычислительную нагрузку, является ключевой задачей для дальнейшего развития области.
Преодоление текущего ограничения требует комплексного переосмысления как аппаратных, так и алгоритмических подходов к нейронным вычислениям. Исследования направлены на создание специализированных архитектур, выходящих за рамки традиционной модели фон Неймана, где обработка данных и хранение памяти физически разделены. Это включает в себя разработку памяти, интегрированной непосредственно в вычислительные блоки, а также исследование альтернативных вычислительных парадигм, таких как нейроморфные вычисления, имитирующие структуру и функционирование человеческого мозга. Параллельно ведутся работы по оптимизации самих алгоритмов нейронных сетей — разработке более эффективных моделей, требующих меньше параметров и вычислительных ресурсов для достижения сопоставимой точности. В конечном итоге, совместное развитие аппаратного и программного обеспечения представляется необходимым для дальнейшего прогресса в области искусственного интеллекта и расширения его возможностей на различных платформах, включая мобильные устройства и системы с ограниченными ресурсами.
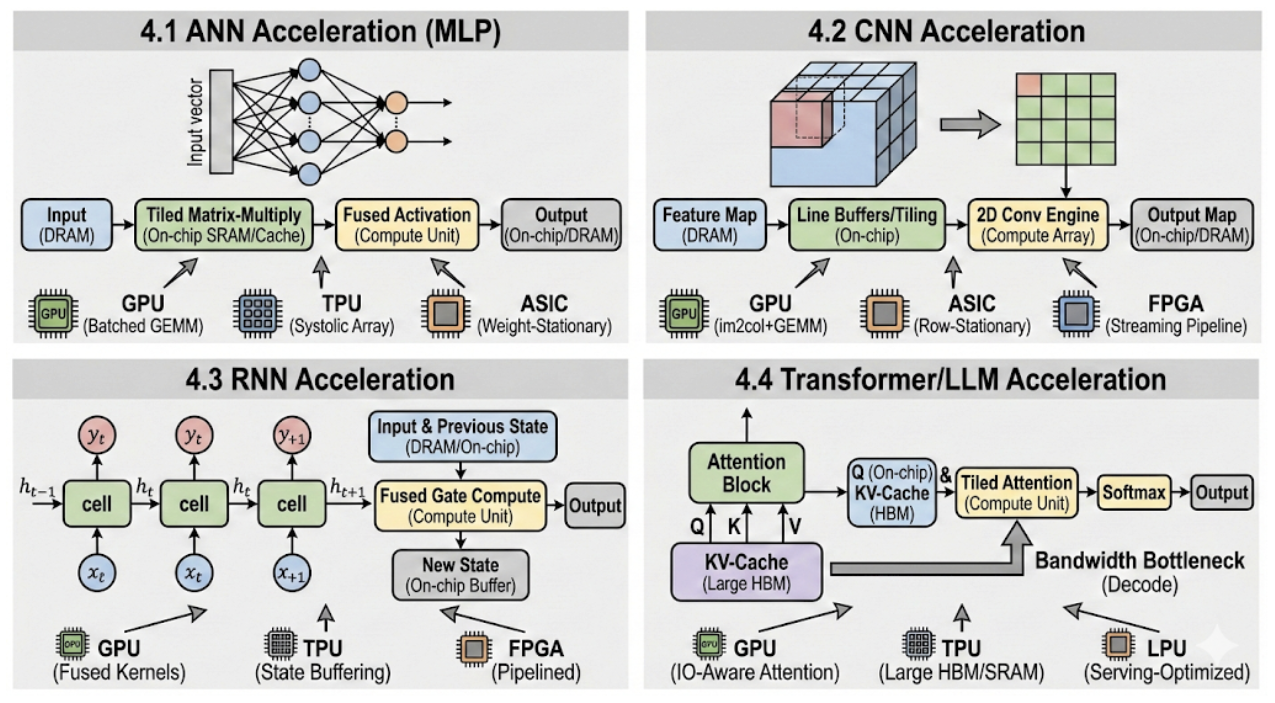
Основы Ускорения: Оптимизация Потока Данных и Доступа к Памяти
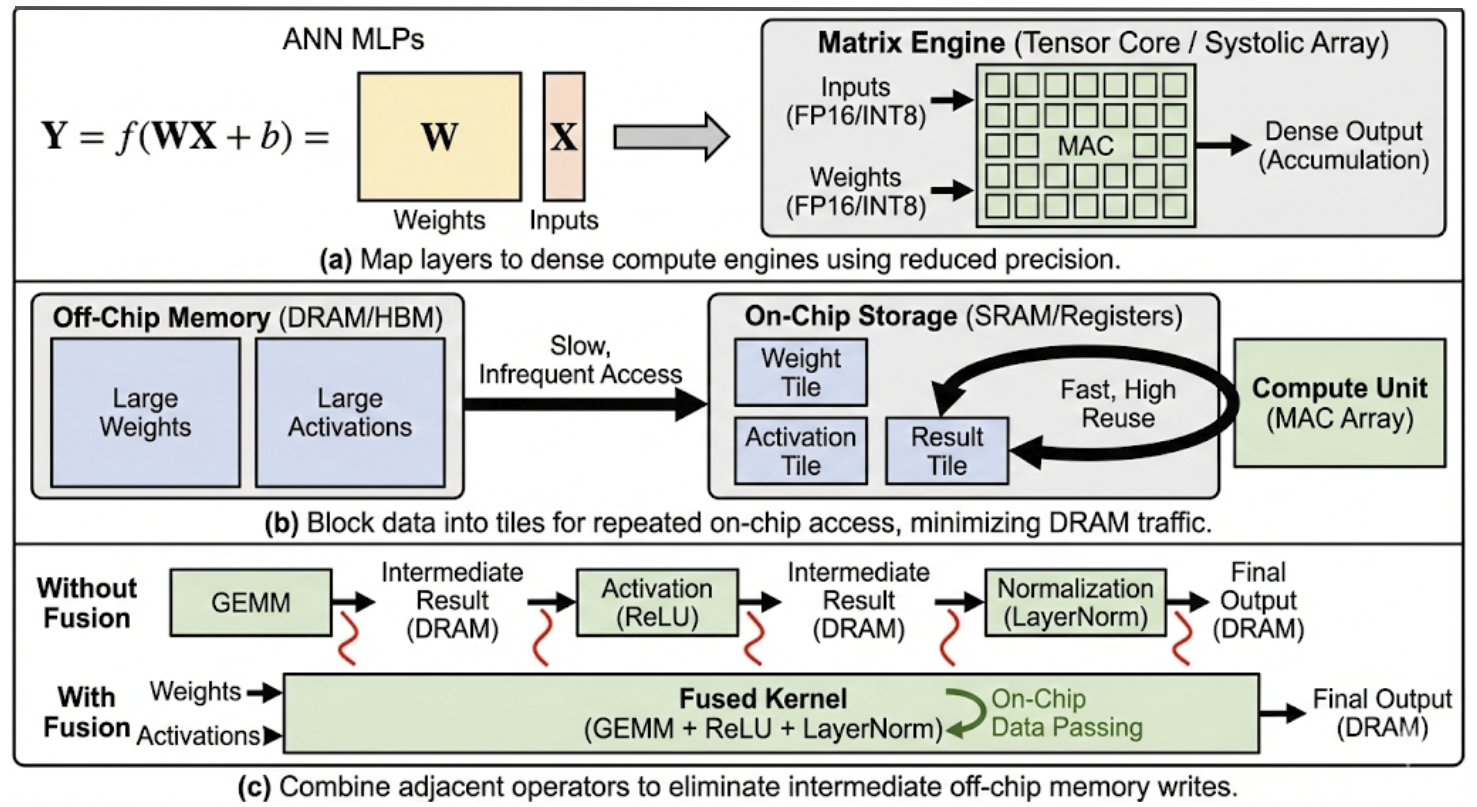
Эффективные аппаратные ускорители нейронных сетей базируются на иерархической системе памяти, предназначенной для максимизации объёма памяти, расположенной непосредственно на кристалле (on-chip), и минимизации обращений к внешней памяти (off-chip). Это обусловлено значительной разницей в скорости доступа и энергопотреблении: доступ к on-chip памяти на порядки быстрее и эффективнее, чем к off-chip. Иерархия обычно включает регистры, SRAM и, возможно, небольшие объемы DRAM, интегрированные на кристалл. Стратегии управления данными направлены на удержание наиболее часто используемых весов и активаций в более быстрых уровнях памяти, чтобы снизить задержки и пропускную способность, необходимые для обмена данными с внешней памятью, такой как DDR или HBM. Оптимизация использования иерархической памяти является ключевым фактором в достижении высокой производительности и энергоэффективности нейронных сетей.
Оптимизация потока данных является критически важной для повышения эффективности нейронных сетевых ускорителей за счет повторного использования данных и минимизации избыточных вычислений. Техники, такие как переупорядочивание операций и изменение порядка доступа к данным, позволяют снизить количество обращений к памяти и увеличить коэффициент использования данных. Например, применение техник tile и loop unrolling позволяет эффективно использовать локальную память, уменьшая задержки и энергопотребление. Кроме того, методы dataflow graph transformations, включая fusion и fission операций, позволяют оптимизировать графы вычислений для конкретной архитектуры ускорителя, сокращая количество необходимых операций и улучшая параллелизм. Эффективная оптимизация потока данных позволяет существенно повысить производительность и энергоэффективность нейронных сетей.
Эффективное планирование рабочей нагрузки является критически важным для оптимизации производительности нейросетевых ускорителей. Оно предполагает динамическое распределение задач между доступными вычислительными ресурсами, с целью максимизировать степень их загруженности и минимизировать время простоя. Грамотное планирование позволяет избежать конфликтов за ресурсы, таких как функциональные блоки и память, что существенно снижает задержки. Алгоритмы планирования учитывают зависимости между задачами, приоритеты и характеристики рабочей нагрузки, обеспечивая оптимальную последовательность выполнения операций. Применение стратегий, таких как статический и динамический планировщики, позволяет адаптироваться к различным типам задач и оптимизировать использование ресурсов в реальном времени.
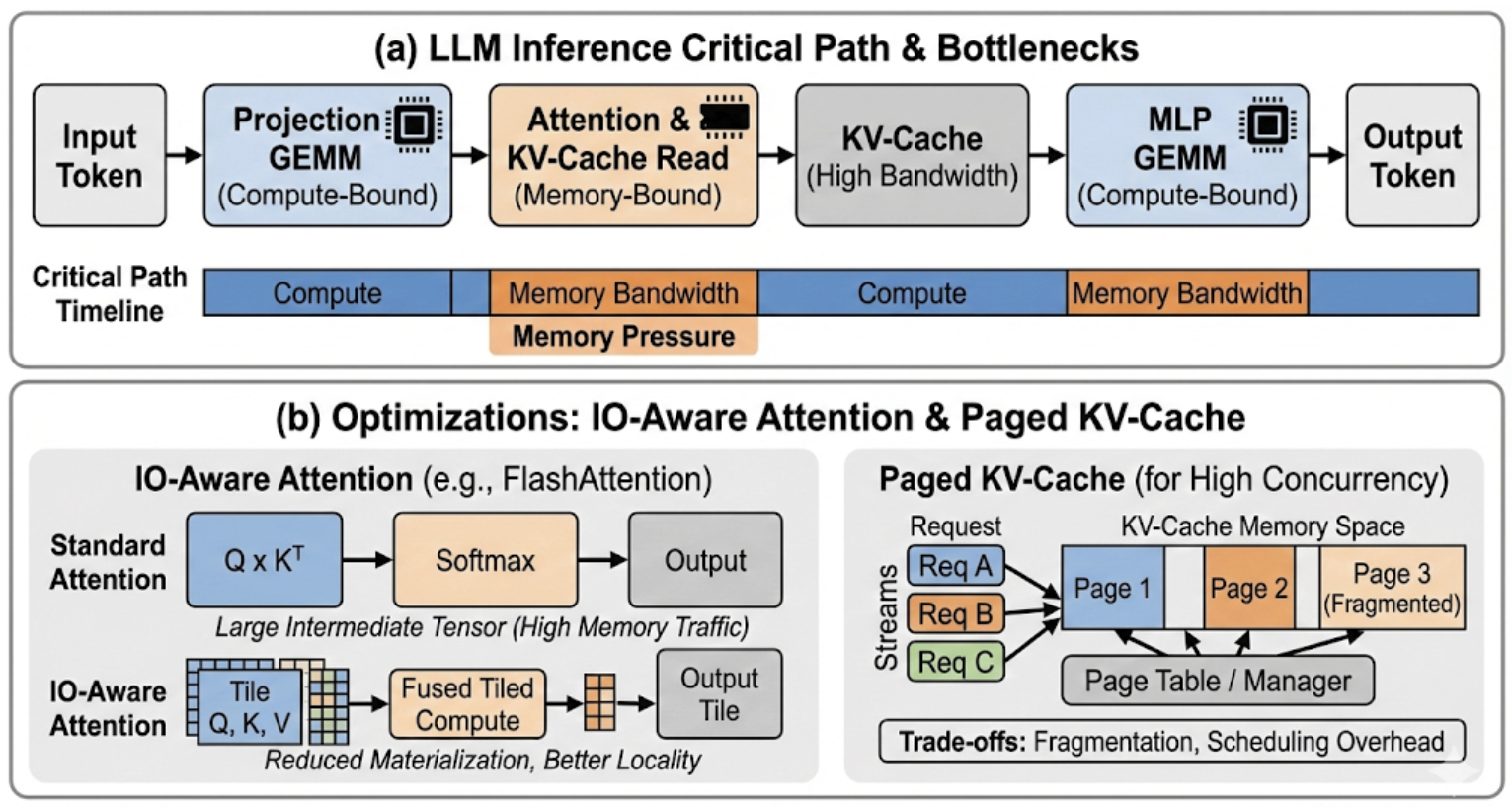
Анализ “крыши” (Roofline analysis) представляет собой методологию для выявления узких мест в производительности, связанных с вычислительной мощностью и пропускной способностью памяти. Данный подход основывается на построении графиков, где одна ось представляет пиковую вычислительную производительность ( FLOPS ), а другая — пиковую пропускную способность памяти ( GB/s ). “Крыша” на графике определяется как минимальное значение между этими двумя параметрами. Производительность приложения ограничивается этой “крышей” — если потребность в вычислениях ниже пропускной способности памяти, узким местом является вычислительная мощность, и наоборот. Анализ позволяет определить, является ли приложение “memory-bound” (ограничено пропускной способностью памяти) или “compute-bound” (ограничено вычислительной мощностью), и направить усилия по оптимизации на устранение соответствующего узкого места.
Архитектурная Специализация: Адаптация Оборудования к Разнообразию Рабочих Нагрузок
Специализированные архитектуры (DSA) демонстрируют превосходную производительность и энергоэффективность за счет использования внутренней структуры конкретных рабочих нагрузок. В отличие от универсальных процессоров, DSA оптимизированы для выполнения ограниченного набора задач, что позволяет значительно сократить количество необходимых вычислительных ресурсов и операций. Это достигается путем аппаратной реализации специфических алгоритмов и структур данных, наиболее часто используемых в целевой области применения. В результате, DSA способны обрабатывать данные быстрее и потреблять меньше энергии, чем универсальные решения, особенно при выполнении повторяющихся и ресурсоемких операций, характерных для определенных классов задач, таких как обработка изображений или машинное обучение.
Специализированные интегральные схемы (ASIC) демонстрируют высокую эффективность при аппаратной реализации конкретных моделей нейронных сетей, таких как свёрточные нейронные сети (CNN). Оптимизация на уровне аппаратного обеспечения позволяет добиться значительного прироста производительности и снижения энергопотребления по сравнению с универсальными процессорами, поскольку архитектура ASIC разрабатывается с учетом специфических операций и структуры данных, характерных для целевой модели. Это достигается за счет жесткого кодирования алгоритмов и данных непосредственно в аппаратную часть, исключая накладные расходы, связанные с интерпретацией инструкций и управлением памятью, что особенно критично для задач, требующих высокой пропускной способности и низких задержек.
Растущее разнообразие моделей нейронных сетей обуславливает необходимость гибкого подхода к проектированию специализированных архитектур (DSA). Традиционные DSA, оптимизированные под конкретную модель или задачу, становятся менее эффективными при изменении требований. Современные нейросети демонстрируют широкий спектр архитектур — от сверточных нейронных сетей (CNN) до рекуррентных (RNN) и трансформеров — каждая из которых имеет свои особенности и требования к вычислительным ресурсам. Поэтому, для обеспечения оптимальной производительности и энергоэффективности в условиях постоянно меняющегося ландшафта нейросетевых моделей, требуется проектирование DSA, способных к адаптации и переконфигурации без значительных аппаратных изменений.
Необходимость баланса между специализацией и программируемостью архитектур обусловлена растущим разнообразием нейронных сетей и задач машинного обучения. Полностью специализированные аппаратные решения, такие как ASIC, демонстрируют высокую производительность для конкретных моделей, однако их негибкость затрудняет адаптацию к новым или изменяющимся алгоритмам. С другой стороны, полностью программируемые решения, например, GPU, обладают универсальностью, но уступают в эффективности специализированным решениям. Таким образом, современные архитектуры стремятся к компромиссу, предлагая возможность настройки и оптимизации для определенных классов задач, сохраняя при этом достаточный уровень программируемости для поддержки будущих инноваций и изменений в алгоритмах.
Алгоритмическая Эффективность: Разреженность и Снижение Точности
Вычислительная разреженность (Sparse Computing) основывается на том, что большинство современных нейронных сетей содержат значительное количество нулевых параметров (весов и активаций). Вместо обработки всех параметров, разреженные вычисления фокусируются только на ненулевых, что существенно снижает как вычислительную сложность, так и потребность в памяти. Это достигается путем использования специальных форматов хранения данных, оптимизированных для разреженных матриц, и алгоритмов, которые эффективно пропускают нулевые значения. Эффект особенно заметен в больших моделях, где доля нулевых параметров может достигать 90% и более, что приводит к значительному ускорению операций и снижению энергопотребления.
Методы квантизации и прунинга позволяют существенно уменьшить размер и энергопотребление моделей нейронных сетей. Квантизация снижает точность представления весов и активаций, например, с 32-битной плавающей точки до 8-битного целого числа, что приводит к уменьшению объема памяти и ускорению вычислений. Прунинг, в свою очередь, удаляет наименее значимые веса из модели, создавая разреженные матрицы и снижая вычислительную сложность. Комбинирование этих техник позволяет добиться значительного сжатия модели без существенной потери точности, что особенно важно для развертывания моделей на устройствах с ограниченными ресурсами.
Комбинация разреженности и снижения точности позволяет значительно повысить производительность и энергоэффективность нейронных сетей, особенно на устройствах с ограниченными ресурсами. Разреженность, удаляя несущественные связи, уменьшает объем вычислений и потребление памяти. Снижение точности, переходя от 32-битных чисел с плавающей запятой к 8-битным целым числам или даже меньше, дополнительно сокращает требования к памяти и пропускной способности, а также может ускорить вычисления на специализированном оборудовании. Совместное применение этих методов приводит к экспоненциальному снижению вычислительных затрат и потребления энергии, делая развертывание сложных моделей машинного обучения возможным на мобильных устройствах, встроенных системах и других ресурсоограниченных платформах. Например, уменьшение точности весов и активаций с одновременным удалением незначительных связей может уменьшить размер модели в несколько раз, сохранив при этом приемлемый уровень точности.
Для моделей Transformer методы разреженного внимания (Sparse Attention) и IO-зависимого внимания (IO-Aware Attention) обеспечивают существенное снижение требований к пропускной способности памяти и вычислительной сложности. Традиционный механизм внимания требует вычисления взаимодействия между каждой парой токенов, что приводит к квадратичной зависимости от длины последовательности O(n^2). Разреженное внимание ограничивает эти взаимодействия, рассматривая только подмножество пар токенов, выбранных на основе различных критериев, таких как близость или структура. IO-зависимое внимание оптимизирует доступ к памяти, учитывая паттерны чтения и записи, что позволяет сократить время задержки и повысить эффективность использования кэша. Комбинированное применение этих методов позволяет значительно уменьшить как вычислительные затраты, так и объем используемой памяти, особенно при работе с длинными последовательностями.
Будущее Ускорения: К Устойчивому Искусственному Интеллекту
Вычислительные подходы, известные как вычисления в памяти (In-Memory Computing) и вблизи памяти (Near-Memory Computing), представляют собой перспективное направление для значительного снижения энергопотребления и повышения эффективности систем искусственного интеллекта. Традиционные архитектуры компьютеров сталкиваются с проблемой «узкого места» при перемещении данных между процессором и памятью, что требует значительных затрат энергии и времени. Данные подходы предлагают выполнять вычисления непосредственно внутри или в непосредственной близости от чипов памяти, что минимизирует необходимость перемещения данных и, как следствие, значительно сокращает энергозатраты. Вместо передачи данных к процессору для обработки, операции выполняются там, где хранятся данные, что открывает возможности для создания более быстрых, энергоэффективных и масштабируемых систем для широкого спектра приложений, включая обработку больших данных, машинное обучение и компьютерное зрение.
Проектирование современных ускорителей искусственного интеллекта требует не просто повышения производительности, но и тщательного баланса между несколькими ключевыми параметрами. Оптимизация исключительно по скорости работы часто приводит к значительному увеличению энергопотребления, стоимости и занимаемой площади чипа. Многоцелевая оптимизация, напротив, позволяет одновременно учитывать все эти факторы, находя компромиссные решения, максимально отвечающие конкретным требованиям применения. Этот подход позволяет создавать ускорители, которые эффективно работают на различных платформах — от мобильных устройств с ограниченными ресурсами до крупных центров обработки данных. Современные алгоритмы оптимизации, учитывающие взаимосвязи между производительностью, энергоэффективностью, стоимостью и площадью, становятся неотъемлемой частью процесса проектирования, обеспечивая создание устойчивых и экономически выгодных решений в области искусственного интеллекта.
Сближение специализированных архитектур, повышения эффективности алгоритмов и внедрение новых типов памяти является ключевым фактором для создания устойчивого искусственного интеллекта. Традиционные вычислительные системы сталкиваются с ограничениями, связанными с энергопотреблением и передачей данных. Вместе с тем, разработка аппаратного обеспечения, адаптированного под конкретные задачи ИИ, в сочетании с оптимизацией алгоритмов для минимизации вычислительной нагрузки, и использование перспективных технологий памяти, таких как энергонезависимая память и вычисления в памяти, позволяет значительно сократить энергопотребление и повысить производительность. Этот симбиоз позволит развертывать мощные приложения искусственного интеллекта на широком спектре устройств — от мобильных телефонов до крупных центров обработки данных — делая ИИ более доступным и экологичным.
Разработка более эффективных AI-ускорителей открывает возможности для внедрения мощных алгоритмов искусственного интеллекта на широком спектре устройств. От компактных мобильных телефонов, способных выполнять сложные задачи обработки изображений и естественного языка непосредственно на устройстве, до крупных центров обработки данных, требующих высокой производительности для анализа огромных массивов информации — новые архитектуры и технологии позволяют преодолеть ограничения, связанные с энергопотреблением и вычислительными ресурсами. Это означает, что сложные модели машинного обучения, ранее доступные только в облаке, смогут функционировать локально, обеспечивая повышенную конфиденциальность, снижение задержек и возможность работы в условиях ограниченной связи. Подобное расширение возможностей AI способствует развитию инноваций в различных областях, включая автономные системы, медицину, финансы и научные исследования.
Исследование аппаратного ускорения нейронных сетей демонстрирует сложную взаимосвязь между производительностью, энергоэффективностью и разнообразием рабочих нагрузок. Стремление к оптимизации этих параметров требует не добавления новых слоев абстракции, а, напротив, очищения архитектуры от избыточности. Как отмечал Юрген Хабермас: «Коммуникативное действие — это не просто передача информации, а достижение взаимопонимания посредством рациональной аргументации». Аналогично, в проектировании ускорителей необходимо стремиться к ясности и эффективности, чтобы обеспечить оптимальное взаимодействие между аппаратным обеспечением и алгоритмами, устраняя все лишнее и фокусируясь на достижении взаимопонимания между компонентами системы. Отказ от избыточности — ключ к совершенству в данной области.
Что дальше?
Представленный обзор, как и любая попытка систематизировать быстротечность прогресса, неизбежно выявляет не столько завершенные задачи, сколько четче очерченные границы незнания. Стремление к ускорению нейронных сетей, подобно гонке за горизонтом, переносит акцент с простой скорости на проблему её стоимости — энергетической, вычислительной, концептуальной. Разнообразие рабочих нагрузок, эта хаотичная симфония задач, требует не универсальных решений, а гибких, адаптивных архитектур. Игнорирование этого принципа — ненужное насилие над вниманием исследователя.
Оптимизации потока данных и вычислений в памяти — это не просто технические ухищрения, а признание фундаментального ограничения: перемещение данных — более дорогостоящая операция, чем сами вычисления. Квантование, как и любая форма упрощения, несёт в себе риск потери информации. Поиск баланса между точностью и эффективностью требует не слепого следования трендам, а строгого математического анализа. Плотность смысла — новый минимализм в проектировании аппаратного обеспечения.
Будущие исследования, вероятно, сконцентрируются на создании самообучающихся аппаратных платформ, способных адаптироваться к меняющимся требованиям рабочих нагрузок. Однако, истинный прогресс не в увеличении количества транзисторов, а в уменьшении количества ненужных. Сложность — это тщеславие. Ясность — милосердие.
Оригинал статьи: https://arxiv.org/pdf/2512.23914.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Квантовые нейросети на службе нефтегазовых месторождений
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Квантовая криптография: от теории к практике
- Робот, который видит, понимает и действует: новая эра общего назначения
- Лунный гелий-3: Охлаждение квантового будущего
- Квантовые сети для моделирования молекул: новый подход
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые прорывы: Хорошее, плохое и смешное
2026-01-01 06:50