Автор: Денис Аветисян
Новая работа предлагает структурированный подход к анализу процессов извлечения информации и логических рассуждений, необходимых для ответа на многоступенчатые вопросы.
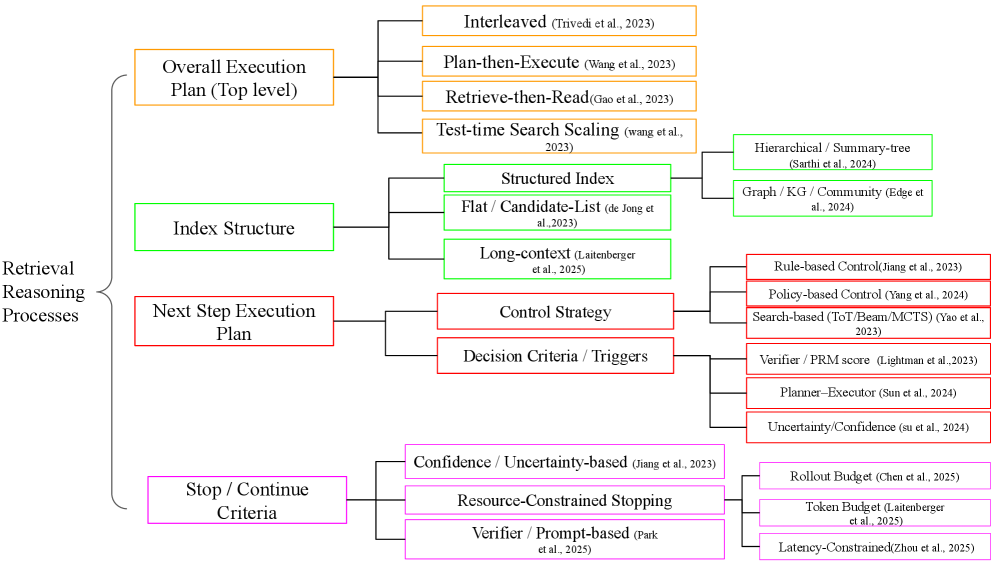
Предложена четырехфакторная структура для анализа и сравнения различных подходов к комбинированию поиска и рассуждений в задачах многоступенчатого вопросно-ответного взаимодействия.
Многоступенчатое вопросно-ответное взаимодействие требует от систем итеративного поиска доказательств и логических выводов, однако лежащие в основе процессов поиска и рассуждений часто остаются неявными, затрудняя сравнение различных моделей. В настоящем обзоре, озаглавленном ‘Retrieval—Reasoning Processes for Multi-hop Question Answering: A Four-Axis Design Framework and Empirical Trends’, предлагается четырехмерная структура для анализа процедур поиска и рассуждений, охватывающая план выполнения, структуру индекса, стратегии управления следующим шагом и критерии остановки. С помощью этой схемы авторы систематизируют существующие подходы к многоступенчатому вопросно-ответному взаимодействию и выявляют компромиссы между эффективностью, скоростью и достоверностью доказательств. Какие новые направления исследований позволят создать более надежные и эффективные агенты, способные к поиску и рассуждениям в условиях меняющихся данных?
Разоблачение Закономерностей: Вызов Глубокого Рассуждения
Современные языковые модели демонстрируют впечатляющую способность к распознаванию закономерностей в данных, однако испытывают значительные трудности при решении задач, требующих многоступенчатого логического вывода, таких как ответы на сложные вопросы. В то время как модели эффективно оперируют поверхностными связями между понятиями, им часто не хватает способности к глубокому анализу и синтезу информации, необходимому для установления сложных причинно-следственных связей. Это проявляется в неспособности корректно отвечать на вопросы, требующие объединения информации из нескольких источников или проведения логических умозаключений на основе имеющихся знаний. По сути, модели преуспевают в запоминании и воспроизведении шаблонов, но испытывают затруднения в ситуациях, требующих гибкого мышления и адаптации к новым, не встречавшимся ранее комбинациям данных.
Несмотря на значительные успехи в области искусственного интеллекта, простое увеличение масштаба языковых моделей не всегда приводит к пропорциональному улучшению способности к сложному рассуждению. Исследования показывают, что после определенного порога увеличение числа параметров сталкивается с вычислительными ограничениями и законом убывающей доходности. Это связано с тем, что большая часть вычислительных ресурсов тратится на обработку огромного объема данных, а не на углубленный анализ и выявление логических связей. Таким образом, дальнейшее наращивание масштаба моделей без одновременного развития новых архитектур и алгоритмов, способных эффективно использовать эти ресурсы, оказывается неэффективным и приводит к экспоненциальному росту затрат без существенного прогресса в решении задач, требующих многоступенчатого логического вывода.
Традиционные подходы к извлечению знаний зачастую рассматривают информационные ресурсы как нечто статичное, что препятствует эффективному решению задач, требующих многоступенчатого рассуждения. Вместо того, чтобы адаптировать процесс поиска информации в зависимости от хода умозаключений, системы, как правило, предоставляют фиксированный набор данных, не учитывая, что при каждом новом шаге рассуждения потребность в знаниях может меняться. Такой подход приводит к избыточному объему нерелевантной информации или, наоборот, к отсутствию критически важных данных на определенном этапе. Современные исследования направлены на создание систем, способных динамически адаптировать стратегии поиска и извлечения знаний, учитывая контекст рассуждений и изменяющиеся потребности в информации, что позволяет значительно повысить эффективность решения сложных задач.
Явный Цикл: Рассуждение и Поиск в Гармонии
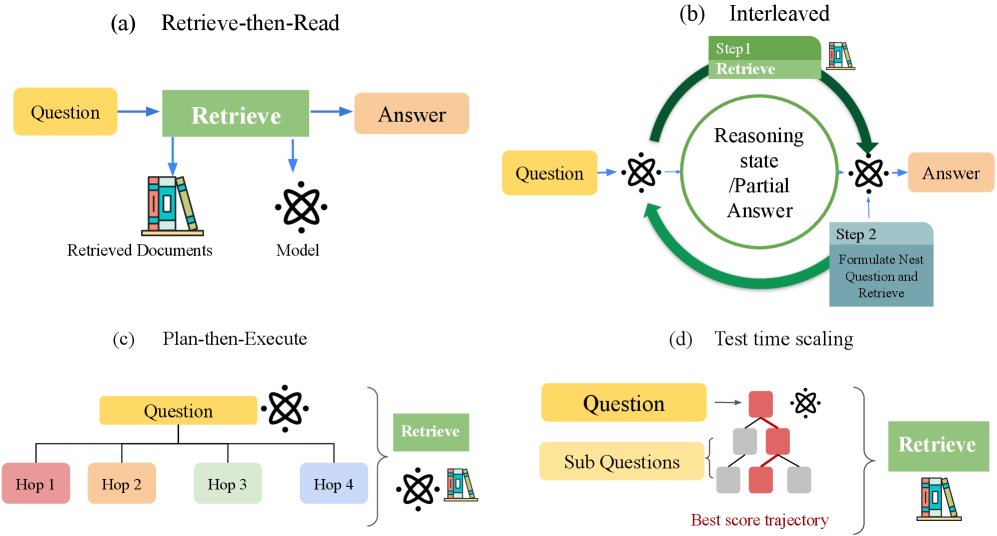
Ключевым аспектом является создание явного цикла взаимодействия между процессами рассуждения и поиска информации, позволяющего модели активно запрашивать данные, релевантные текущему ходу мыслей. В отличие от подходов “поиск-затем-чтение”, где поиск осуществляется как единовременный этап предварительной обработки, данный цикл обеспечивает динамическую адаптацию в процессе рассуждения. Модель, в рамках этого цикла, формирует запросы на основе промежуточных выводов, получает релевантную информацию и интегрирует ее в дальнейший процесс рассуждения, что позволяет ей уточнять и расширять свои знания в ходе решения задачи.
В отличие от подходов «сначала извлечение, затем чтение», где поиск информации осуществляется как единичный этап предварительной обработки, текущая архитектура позволяет модели адаптироваться в процессе рассуждений. В традиционных системах весь необходимый контекст извлекается до начала логической цепочки, что ограничивает возможность получения новой информации при обнаружении противоречий или неполноты исходных данных. В результате, модель не может динамически корректировать свои рассуждения на основе вновь полученных знаний, что снижает общую эффективность и точность вывода.
Взаимодействие процессов извлечения информации и рассуждений позволяет создать динамический процесс приобретения знаний, имитирующий когнитивную гибкость человека. В отличие от статических подходов, где информация извлекается однократно перед началом рассуждений, данная схема предполагает циклический обмен между этапами. Модель, в процессе рассуждения, формирует запрос к внешним источникам, получает релевантную информацию и интегрирует ее в текущий контекст, что позволяет корректировать ход мысли и учитывать новые данные. Такая организация позволяет модели адаптироваться к изменяющимся требованиям задачи и эффективно использовать знания, доступные из внешних источников, подобно тому, как это делает человек в процессе решения сложных задач.
Четырехмерный Фреймворк: Архитектура Интеллекта
Предлагаемый нами четырехмерный фреймворк проектирования охватывает четыре ключевых аспекта: общий план выполнения (Overall Execution Plan), структуру индекса (Index Structure), план выполнения следующего шага (Next-Step Execution Plan) и критерии остановки/продолжения (Stop/Continue Criteria). Общий план определяет общую стратегию работы системы. Структура индекса влияет на эффективность поиска и объем доступных знаний. План выполнения следующего шага определяет, как модель выбирает следующее действие — запрос дополнительной информации или продолжение рассуждений. Критерии остановки/продолжения необходимы для предотвращения бесконечных циклов и обеспечения эффективного использования ресурсов. В совокупности эти четыре оси формируют основу для разработки и оценки систем, работающих с большими объемами информации и требующих сложных рассуждений.
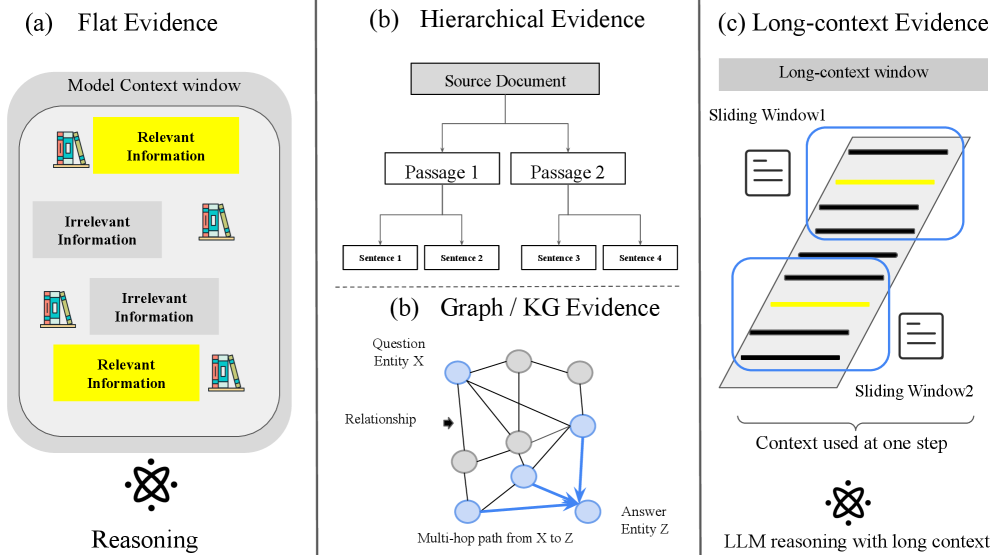
Различные структуры индексов, такие как плоские списки кандидатов (Flat Candidate Lists) или иерархические индексы, оказывают существенное влияние на эффективность поиска и объем получаемого доступа к знаниям. Плоские списки обеспечивают быстрый доступ к данным, но масштабируемость ограничена, особенно при работе с большими объемами информации. Иерархические индексы, напротив, позволяют эффективно организовывать данные по категориям, обеспечивая более широкий охват, но могут потребовать дополнительных вычислительных затрат при поиске. Выбор структуры индекса напрямую зависит от конкретных требований системы, объема данных и необходимой скорости доступа.
Планы последовательных действий, использующие стратегии обучения с подкреплением или правила, определяют, как модель выбирает следующее действие — запрос дополнительной информации или продолжение рассуждений. Анализ 104 научных работ показал, что 51,0% систем используют глобальные политики управления, основанные на обучении. Эти политики позволяют модели динамически адаптировать стратегию поиска и рассуждений в зависимости от текущего состояния и целей, в отличие от фиксированных, предопределенных правил.
Критерии остановки и продолжения работы, такие как ограничение ресурсов или верификация, играют важную роль в предотвращении бесконечных циклов и обеспечении эффективного использования вычислительных ресурсов. Анализ 104 исследовательских работ показал, что 93,3% систем используют механизмы остановки, основанные на ограничении ресурсов, что свидетельствует о преобладании данного подхода в современных архитектурах. Эти механизмы ограничивают время выполнения, объем используемой памяти или количество запросов к внешним источникам, гарантируя завершение процесса даже в случае неудачной или затянутой обработки.
Эмпирическая Валидация и Дальнейшее Влияние
Применение разработанной структуры к наборам данных, таким как HotpotQA, 2WikiMultiHopQA и MuSiQue, продемонстрировало существенное повышение точности при решении задач многошагового вопросно-ответного поиска. В ходе экспериментов зафиксировано значительное улучшение показателей по сравнению с существующими подходами, что свидетельствует об эффективности предложенного метода в обработке сложных запросов, требующих синтеза информации из различных источников. Повышение точности особенно заметно в задачах, где требуется установление сложных логических связей между фактами, что подтверждает способность системы к более глубокому пониманию и анализу информации. Данные результаты указывают на перспективность использования предложенной структуры для создания более интеллектуальных систем, способных эффективно решать сложные когнитивные задачи.
В рамках разработанного подхода к выполнению задач, стратегия масштабирования поиска во время выполнения позволяет исследовать множество возможных путей рассуждений. Данный механизм не ограничивается единственным направлением анализа, а активно прорабатывает альтернативные сценарии, что значительно повышает устойчивость системы к ошибкам и снижает вероятность застревания в неоптимальных решениях. По сути, система способна «прощупывать» различные варианты ответа, оценивая их правдоподобность и выбирая наиболее обоснованный, что особенно важно при решении сложных, многоступенчатых вопросов, требующих глубокого анализа и синтеза информации. Такая гибкость в процессе поиска и рассуждений позволяет добиться более надежных и точных результатов, даже в условиях неполных или противоречивых данных.
Разработки, представленные в данной работе, открывают новые возможности для систем генерации с использованием извлечения информации (Retrieval-Augmented Generation) и систем, функционирующих как интеллектуальные агенты. Повышенная точность и надежность извлечения знаний, достигаемая благодаря моделированию процесса поиска и рассуждений, позволяет этим системам решать сложные задачи, требующие обширных знаний, с беспрецедентной эффективностью. В частности, улучшенное понимание контекста и способность исследовать различные пути рассуждений значительно повышают качество генерируемых ответов и действий, обеспечивая более обоснованные и точные результаты в задачах, связанных с обработкой информации и принятием решений. Это, в свою очередь, способствует созданию более интеллектуальных и адаптивных систем, способных успешно функционировать в сложных и динамичных средах.
Результаты всестороннего анализа 252 научных работ и детального изучения 104 из них показали, что 53,8% существующих систем, решающих задачи, требующие работы со знаниями, по-прежнему используют последовательный подход “извлечение-затем-чтение”. Это означает, что информация сначала извлекается из внешних источников, а затем уже обрабатывается для получения ответа. Данный подход, хотя и широко распространен, ограничивает возможности систем в динамической адаптации к сложным запросам и может приводить к неоптимальным решениям. Выявленная тенденция подчеркивает значительный потенциал для развития более продвинутых стратегий извлечения информации, способных интегрироваться с процессом рассуждения и обеспечивать более точные и эффективные результаты.
Явное моделирование процесса извлечения информации и последующего рассуждения открывает новые перспективы для создания более прозрачных и управляемых систем искусственного интеллекта. Традиционно, многие модели функционируют как “черные ящики”, затрудняя понимание логики принятия решений. Предлагаемый подход позволяет не просто получить ответ, но и проследить, какие конкретно источники информации были использованы и как они повлияли на формирование заключения. Это, в свою очередь, способствует повышению доверия к системе, облегчает выявление и исправление ошибок, а также предоставляет возможность пользователю контролировать процесс рассуждения, направляя его в нужное русло. Такой уровень интерпретируемости и управляемости является ключевым для внедрения ИИ в критически важные области, где требуется не только точность, но и возможность объяснить и обосновать принятые решения.
Исследование процессов извлечения и рассуждений в задачах многошагового вопросно-ответного анализа демонстрирует стремление к систематизации, к выявлению фундаментальных осей, определяющих эффективность подхода. Эта работа, по сути, представляет собой попытку декомпозировать сложную систему на отдельные компоненты для более глубокого понимания её работы. Как однажды заметил Карл Фридрих Гаусс: «Если бы я должен был выбирать между тем, чтобы быть математиком или поэтом, я бы выбрал математику». Эта фраза отражает подход, представленный в статье: стремление к точности, структуре и выявлению скрытых закономерностей, что необходимо для создания эффективных систем извлечения и рассуждений, особенно в контексте многошагового вопросно-ответного анализа.
Куда же дальше?
Предложенная здесь четырёхосная схема — это не столько финальный ответ, сколько инструмент для деконструкции. Попытка разложить сложный процесс поиска и рассуждений на отдельные оси — любопытный ход, но истинная ценность кроется не в самой типологии, а в осознании её искусственности. Понимание, что любая классификация — это всегда упрощение, своего рода «чёрный ящик» с наклеенными ярлыками, открывает путь к поиску подлинных закономерностей, скрытых за видимостью порядка.
Следующим шагом видится отказ от поиска «идеальной» архитектуры. Более продуктивным представляется исследование принципов самоорганизации в системах «вопрос-ответ». Вместо того чтобы навязывать жесткие рамки, необходимо позволить системе эволюционировать, адаптироваться, находить собственные, возможно, нелогичные, но эффективные решения. Ведь часто именно в хаосе скрываются ключи к пониманию сложных процессов.
Особый интерес представляет анализ ошибок. Не «исправление» ошибок, а их детальное изучение как источника информации. Почему система пришла к неверному выводу? Какие «слепые зоны» в её алгоритмах позволили возникнуть этой ошибке? Именно в этих «сбоях» кроется понимание её внутренней логики, её реальной природы. И, возможно, именно там — ключ к созданию чего-то принципиально нового.
Оригинал статьи: https://arxiv.org/pdf/2601.00536.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Лунный гелий-3: Охлаждение квантового будущего
- Квантовые сети для моделирования молекул: новый подход
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовые прорывы: Хорошее, плохое и смешное
- Метаболический профиль СДВГ: новый взгляд на диагностику
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
2026-01-05 20:08