Автор: Денис Аветисян
Исследователи представили динамичный бенчмарк, позволяющий оценить способность языковых моделей к логическому мышлению и решению задач из области физики.

SymPyBench — это инструмент для оценки точности, последовательности и обобщающей способности моделей при решении разнообразных физических задач с использованием исполняемого Python-кода.
Несмотря на успехи современных больших языковых моделей, оценка их способностей к логическому мышлению и решению научных задач остается сложной проблемой. В данной работе представлен ‘SymPyBench: A Dynamic Benchmark for Scientific Reasoning with Executable Python Code’ — масштабный синтетический набор данных, включающий 15 045 задач по физике университетского уровня, с параметризованными условиями и эталонными решениями, реализованными в виде исполняемого Python-кода. Введены новые метрики для оценки не только точности, но и согласованности и обобщающей способности моделей при решении вариаций задач. Позволит ли SymPyBench создать более надежные и интерпретируемые системы научного мышления и преодолеть ограничения существующих бенчмарков?
Вызов Научного Рассуждения для Больших Языковых Моделей
Несмотря на впечатляющие способности в обработке и генерации языка, современные большие языковые модели (LLM) часто демонстрируют неустойчивость в задачах, требующих научного рассуждения. Вместо логического вывода, основанного на физических принципах, модели склонны к “галлюцинациям” — генерации неверных, а порой и бессмысленных решений, которые могут выглядеть правдоподобно, но не соответствуют действительности. Это особенно заметно при решении сложных физических задач, где требуется не просто знание формул, таких как $E=mc^2$, но и умение применять их в конкретных ситуациях, учитывая все необходимые условия и ограничения. Такая неспособность к надёжному научному рассуждению существенно ограничивает возможности применения LLM в областях, где точность и достоверность информации критически важны.
Существующие стандартные тесты для оценки способностей языковых моделей решать физические задачи часто оказываются недостаточно глубокими и строгими. Многие из них концентрируются на простом воспроизведении известных фактов или применении готовых формул, не требуя от модели настоящего понимания физических принципов и умения применять их в новых, нестандартных ситуациях. Например, модель может успешно решить задачу на применение $F = ma$, если она просто встретилась в обучающем наборе, но потерпеть неудачу при незначительном изменении условий или при необходимости объединить несколько физических концепций. Это создает иллюзию компетентности, поскольку модель демонстрирует успехи в узком спектре задач, но не обладает надежной способностью к решению сложных и неоднозначных проблем, характерных для реальной научной деятельности.
Для успешного применения больших языковых моделей (LLM) в научных областях требуется не просто генерация текста, а надёжное и проверяемое рассуждение. В отличие от областей, где небольшие неточности допустимы, научные выводы должны быть обоснованы и подтверждены, ведь даже незначительная ошибка в физической или химической модели может привести к серьезным последствиям. Поэтому, ключевым требованием к LLM, используемым в науке, является способность не только предлагать решения, но и демонстрировать ход мыслей, позволяющий верифицировать правильность полученных результатов и отслеживать логическую цепочку, приведшую к данному выводу. Без такой возможности, LLM рискуют стать источником дезинформации, а не инструментом для научных открытий, что подчеркивает необходимость разработки методов, обеспечивающих прозрачность и надёжность их рассуждений.

SymPyBench: Строгий Фреймворк для Оценки
SymPyBench представляет собой динамичный набор тестов, состоящий из 15 045 физических задач, к каждой из которых приложен исполняемый код на Python. Этот код служит эталонным решением, обеспечивающим возможность верификации и оценки точности работы других систем и моделей, решающих аналогичные задачи. Использование исполняемого кода позволяет автоматизировать процесс проверки и обеспечивает объективную оценку результатов, а большое количество задач гарантирует статистическую значимость получаемых данных. Набор данных предназначен для количественной оценки способности моделей к решению физических задач и может использоваться для сравнения различных подходов.
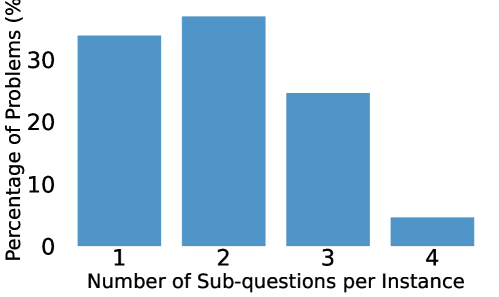
В основе SymPyBench лежит метод параметризации задач, заключающийся в создании множества вариаций исходных физических проблем путём изменения численных значений параметров. Этот подход позволяет оценить способность моделей к обобщению — то есть, к корректному решению задач, незначительно отличающихся от тех, на которых они обучались. Генерируя задачи с разными параметрами, SymPyBench проверяет устойчивость моделей к незначительным изменениям во входных данных и выявляет случаи, когда модель успешно решает только узкий класс задач, заданных конкретными значениями параметров. Количество генерируемых вариаций для каждой задачи варьируется, обеспечивая всестороннюю проверку обобщающей способности и устойчивости моделей.
В SymPyBench для оценки различных аспектов логического мышления используются вопросы двух типов: с множественным выбором ответов и вопросы со свободным ответом. Вопросы с множественным выбором предназначены для проверки способности модели к распознаванию правильного решения среди нескольких предложенных вариантов, что позволяет оценить ее способность к точному применению знаний. Вопросы со свободным ответом требуют от модели самостоятельного генерирования решения, что проверяет ее способность к решению задач, требующих логических выводов и применения знаний в новых ситуациях. Комбинация этих двух типов вопросов позволяет комплексно оценить возможности модели в области решения физических задач и ее способность к обобщению.
Количественная Оценка Рассуждений: Ключевые Метрики
Метрика ‘Exact Match Accuracy’ (точное соответствие) в SymPyBench используется для оценки доли полностью корректных решений, представленных моделями. Данный показатель фиксирует, насколько точно полученный ответ совпадает с эталонным решением. На момент проведения оценки, лучшие модели продемонстрировали результат в 64% по данной метрике, что указывает на уровень точности, достигнутый в решении задач, представленных в бенчмарке SymPyBench. Показатель рассчитывается как отношение количества полностью корректных решений к общему числу представленных решений.
В дополнение к метрике точного совпадения (Exact Match Accuracy), для оценки прогресса в решении задач используется метрика частичной точности (Partial Accuracy). Она позволяет учитывать случаи, когда модель предоставляет неполное, но верное решение или выполняет часть необходимых шагов. На текущий момент, модели Gemini-2.0-Flash достигли показателя в 71.43% по данной метрике, что свидетельствует о способности модели делать существенный прогресс в решении задач, даже если не удается получить абсолютно точный ответ.
Показатель согласованности (Consistency Score) оценивает надежность работы модели при решении вариаций одной и той же задачи. Он измеряет, насколько стабильно модель выдает правильные ответы при незначительных изменениях в исходных данных или формулировке проблемы. При тестировании на наборе задач SymPyBench, модель Anthropic Sonnet-3.7 достигла показателя согласованности в 42.42%, что указывает на умеренную устойчивость ее работы в условиях незначительных изменений в задачах.
Показатель «Частота ошибок» (Confusion Rate) определяет группы задач, в которых модели демонстрируют неуверенность в своих ответах. Этот показатель рассчитывается как доля случаев, когда модель выдает неверный ответ в определенной группе задач, требующих схожих навыков или принципов решения. В ходе тестирования, модель Anthropic Sonnet-3.7 показала частоту ошибок на уровне 6.06%, что указывает на определенные категории задач, где требуется дальнейшая оптимизация для повышения точности и надежности ответов. Анализ групп задач с высокой частотой ошибок позволяет выявить слабые места модели и сосредоточить усилия на улучшении ее способности к решению конкретных типов проблем.

Обеспечение Валидности Решения: Техническая Инфраструктура
Генерация эталонных решений осуществляется посредством выполнения произвольного Python-кода, что позволяет реализовать широкий спектр алгоритмов и подходов к решению задач. Ключевым компонентом является библиотека SymPy, обеспечивающая возможности символьной алгебры, такие как аналитическое решение уравнений, дифференцирование, интегрирование и упрощение выражений. Это позволяет получать не численные, а аналитические решения, представленные в виде математических формул, например, $x = \frac{-b \pm \sqrt{b^2 — 4ac}}{2a}$. Использование SymPy критически важно для задач, требующих точного символьного представления ответа, а не только его численного приближения.
Для обеспечения физической корректности генерируемого кода используется библиотека Pint, осуществляющая контроль согласованности размерностей. Pint позволяет определять и отслеживать единицы измерения физических величин, такие как метры ($m$), килограммы ($kg$) и секунды ($s$), и автоматически проверять, что все операции с величинами проводятся с учетом их размерностей. Это предотвращает возникновение ошибок, связанных с некорректными вычислениями, например, сложение метров с килограммами, и гарантирует, что результаты вычислений имеют физический смысл. Библиотека обеспечивает поддержку широкого спектра единиц измерения и позволяет задавать пользовательские единицы, что делает ее гибким инструментом для работы с физическими задачами.
Извлечение текстовой информации из наборов задач осуществляется с помощью системы оптического распознавания символов (OCR) Tesseract. Данная система позволяет преобразовывать изображения, содержащие текст, в машиночитаемый формат, необходимый для последующей обработки и анализа. Важно отметить, что контент, используемый для обучения и тестирования системы, распространяется под лицензией Creative Commons, что обеспечивает открытый доступ и возможность повторного использования данных в исследовательских и образовательных целях.
Влияние и Перспективы для Научного ИИ
Детальный анализ, проведенный с помощью SymPyBench, выявил существенные ограничения в способностях современных больших языковых моделей (LLM) к логическому мышлению и решению задач, требующих математической точности. Исследование показало, что, несмотря на впечатляющие возможности в обработке естественного языка, LLM часто допускают ошибки в простых математических вычислениях и не способны последовательно применять физические принципы при решении задач. Эти недостатки указывают на необходимость разработки новых архитектур нейронных сетей и усовершенствования стратегий обучения, направленных на повышение способности моделей к дедуктивному мышлению и обеспечению корректности получаемых результатов. В частности, акцент следует сделать на создании моделей, способных к пошаговому рассуждению и проверке своих ответов, что позволит повысить прозрачность и надежность научных расчетов, выполняемых искусственным интеллектом.
Разработка SymPyBench представляет собой значительный шаг вперёд в области научного искусственного интеллекта, поскольку предоставляет стандартизированный инструмент для оценки и сравнения различных моделей. До сих пор, прогресс в этой сфере затруднялся отсутствием общепринятых критериев и методик оценки, что делало сопоставление результатов, полученных разными исследовательскими группами, проблематичным. SymPyBench, предлагая унифицированный набор задач, позволяет объективно оценивать способности моделей к решению математических и физических проблем, выявлять их сильные и слабые стороны, и, таким образом, ускорять развитие более эффективных и надёжных систем искусственного интеллекта, способных к научным открытиям. Этот подход стимулирует конкуренцию и сотрудничество в сообществе, направляя усилия на создание моделей, превосходящих существующие аналоги в решении сложных научных задач.
Дальнейшие исследования в области научных ИИ могут быть направлены на интеграцию более сложных физических концепций, выходящих за рамки базовой математики. Особое внимание уделяется разработке моделей, способных к пошаговому рассуждению — процессу, в котором каждый этап вывода четко сформулирован и обоснован. Такой подход не только повысит точность и надежность научных предсказаний, но и позволит исследователям лучше понимать логику, лежащую в основе работы ИИ, что критически важно для обеспечения прозрачности и доверия к результатам, особенно в областях, где ошибки могут иметь серьезные последствия. В частности, способность модели представлять и манипулировать такими понятиями, как $E=mc^2$ или законы сохранения энергии, может значительно расширить спектр решаемых задач и приблизить ИИ к уровню эксперта-физика.
Представленный труд демонстрирует необходимость оценки языковых моделей не только по способности решать конкретные задачи, но и по их внутренней согласованности и способности к обобщению. Создание динамического бенчмарка SymPyBench позволяет проверить, насколько устойчиво модель применяет физические принципы к разнообразным условиям. Как однажды заметил Джон Маккарти: «Лучший способ сделать что-то сложное — сделать это простым». Именно простота и ясность структуры позволяют оценить истинную надежность системы, а не просто зафиксировать успешное решение отдельных примеров. Подобный подход к оценке, фокусирующийся на фундаментальных принципах и их последовательном применении, представляется особенно важным для развития действительно интеллектуальных систем.
Куда двигаться дальше?
Представленная работа, вводящая SymPyBench, скорее обнажает проблему, чем решает её. Оценка способности больших языковых моделей к научному мышлению неизбежно сводится к измерению их поведения во времени, к динамике ответа на разнообразные, но формально связанные задачи. Однако, само создание «динамического» теста — это лишь попытка зафиксировать неуловимое. Каждая оптимизация, каждое улучшение в архитектуре модели, создает новые точки напряжения, новые области, где кажущаяся «разумность» может обернуться неожиданным провалом.
Важно признать, что истинное научное мышление — это не просто выдача правильного ответа, а способность к самокоррекции, к выявлению и устранению противоречий. SymPyBench — лишь первый шаг к созданию тестов, способных оценить не только точность, но и внутреннюю согласованность моделей, их способность к обобщению за пределами заученных шаблонов. Следующим этапом видится разработка метрик, отражающих не столько «что» модель выдает, сколько «как» она приходит к этому ответу — какие логические цепочки она использует, какие допущения делает.
В конечном счете, архитектура системы определяет её поведение. Создание по-настоящему интеллектуальной системы требует не просто увеличения количества параметров, а глубокого понимания принципов, лежащих в основе научного мышления, и их воплощения в архитектуре модели. Иначе, все усилия по созданию «бенчмарков» останутся лишь тщетной попыткой измерить то, что принципиально не поддается измерению в рамках существующих парадигм.
Оригинал статьи: https://arxiv.org/pdf/2512.05954.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовый скачок: от лаборатории к рынку
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
2025-12-09 03:22