Автор: Денис Аветисян
Исследователи представили уникальный набор данных и бенчмарк для оценки способности ИИ рассуждать на основе сложных научных данных о гелиофизике.

В статье представлен бенчмарк Reasoning With a Star (RWS) и показано, что многоагентные системы могут улучшить научное рассуждение больших языковых моделей.
Несмотря на впечатляющие возможности больших языковых моделей, научное рассуждение в области гелиофизики требует не только извлечения фактов, но и учета физических принципов и соблюдения единиц измерения. В работе «Reasoning With a Star: A Heliophysics Dataset and Benchmark for Agentic Scientific Reasoning» представлен новый набор данных и методика оценки, позволяющие проверить способность моделей к подобному рассуждению. Показано, что декомпозиция задач с использованием многоагентных систем превосходит прямое промптирование в задачах, требующих дедукции, хотя единой оптимальной стратегии координации не выявлено. Какие перспективы открываются для дальнейшего развития систем искусственного интеллекта, способных к полноценному научному исследованию в сложных областях знаний?
Вызов Сложного Рассуждения
Несмотря на впечатляющую способность больших языковых моделей (БЯМ) распознавать закономерности в данных, они часто демонстрируют трудности при решении задач, требующих последовательного логического вывода и многоступенчатого рассуждения. В то время как БЯМ превосходно справляются с идентификацией корреляций и предсказанием на основе известных паттернов, им не хватает способности удерживать в памяти и последовательно применять логические правила для достижения решения. Это проявляется в задачах, где требуется не просто найти соответствие, а построить цепочку умозаключений, учитывая множество взаимосвязанных факторов и условий. В отличие от человеческого мышления, где логические шаги могут быть осознанными и контролируемыми, БЯМ часто полагаются на статистические ассоциации, что приводит к ошибкам в ситуациях, требующих более глубокого понимания и аналитических способностей.
Существующие эталоны, такие как GSM8K и MATH, наглядно демонстрируют ограничения больших языковых моделей (LLM) при решении сложных научно-технических задач. Эти тесты, включающие в себя задачи по математике и физике, требуют не просто извлечения информации из текста, а последовательного применения логических рассуждений и математических операций для достижения верного ответа. Анализ результатов показывает, что LLM часто допускают ошибки в многоступенчатых вычислениях или неверно интерпретируют условия задачи, что свидетельствует о недостаточной способности к абстрактному мышлению и глубокому пониманию предметной области. Таким образом, несмотря на впечатляющие успехи в обработке естественного языка, текущие модели нуждаются в усовершенствовании механизмов, обеспечивающих надежное решение задач, требующих сложных логических построений и точных вычислений, особенно в контексте научных дисциплин.
Неспособность существующих больших языковых моделей к решению сложных задач, требующих последовательного логического вывода, стимулирует разработку принципиально новых архитектур рассуждений. Вместо простого распознавания закономерностей и воспроизведения шаблонов, исследователи стремятся создать системы, способные к построению сложных логических цепочек, анализу промежуточных результатов и адаптации стратегий решения. Такие архитектуры должны выходить за рамки статистического сопоставления данных и демонстрировать истинное понимание проблемы, что позволит им успешно справляться с задачами, требующими не только знания фактов, но и способности к критическому мышлению и абстрактному обобщению. Перспективные направления включают в себя интеграцию символических и нейронных подходов, а также разработку механизмов самопроверки и коррекции ошибок в процессе рассуждений.
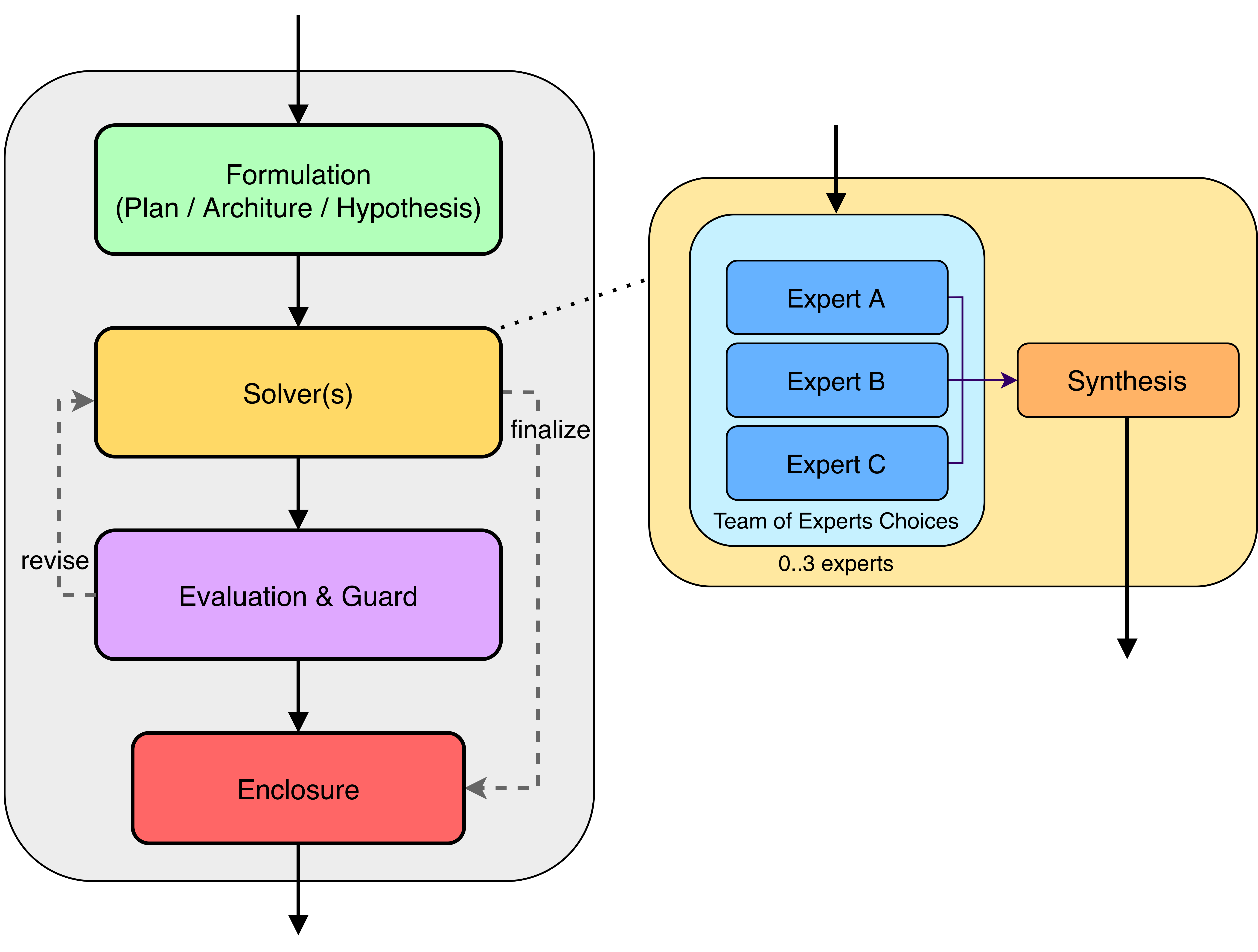
Агент-Ориентированное Рассуждение: Новый Парадигма
В отличие от монолитных больших языковых моделей (LLM), решающих задачи комплексно, агент-ориентированное рассуждение предполагает декомпозицию сложных проблем на последовательность более мелких, управляемых шагов. Каждый шаг выполняется специализированным агентом, предназначенным для конкретной подзадачи. Такой подход позволяет более эффективно использовать вычислительные ресурсы и повышает надежность системы, поскольку ошибки локализованы в отдельных агентах, а не распространяются по всей модели. Использование отдельных агентов также облегчает отладку и модификацию системы, а также обеспечивает возможность параллельной обработки различных этапов решения задачи, что значительно ускоряет процесс.
Тестовый набор Reasoning With a Star (RWS) представляет собой уникальную платформу для оценки систем, основанных на агентском подходе к решению задач. В отличие от стандартных бенчмарков, RWS сфокусирован на сложных сценариях в области гелиофизики, требующих анализа данных солнечной активности, прогнозирования космической погоды и моделирования взаимодействий в солнечной системе. Этот набор задач включает в себя вопросы, требующие не просто извлечения информации, а полноценного планирования действий, анализа сложных данных наблюдений и итеративного уточнения решений для достижения поставленной цели, что делает его ценным инструментом для оценки продвинутых систем искусственного интеллекта.
Тестирование систем на базе бенчмарка Reasoning With a Star (RWS) требует применения методов, выходящих за рамки простого ответа на вопросы. Успешное решение задач в области гелиофизики, представленных в RWS, предполагает, что агенты должны формировать планы действий, анализировать поступающие данные, включающие телеметрическую информацию и результаты моделирования, а также итеративно уточнять свои решения на основе промежуточных результатов и новой информации. Это подразумевает не просто извлечение фактов, а построение логической цепочки рассуждений и адаптацию стратегии решения в процессе работы, что значительно усложняет задачу по сравнению со стандартными задачами вопросно-ответных систем.

Архитектуры для Совместного Рассуждения
Иерархический Многоагентный Рабочий Процесс (HMAW) представляет собой базовый подход к организации совместного рассуждения, где задачи декомпозируются и распределяются между агентами в соответствии с иерархической структурой. Более продвинутые модели, такие как PHASE (Plan, Hypothesize, Assess, Execute) и PACE (Plan, Act, Critique, Evaluate), расширяют этот подход за счет явного включения этапов формирования гипотез и самокритики. PHASE фокусируется на планировании, выдвижении гипотез, их оценке и последующем выполнении, в то время как PACE делает акцент на цикличном процессе планирования, действий, критики и оценки для повышения надежности и эффективности рассуждений.
Архитектура STAR (Systems-engineering-of-Thoughts), основанная на принципах Model-Based Systems Engineering (MBSE), представляет собой надежный механизм координации между агентами. В её основе лежит структурированный подход к решению задач, заимствованный из инженерных практик, что обеспечивает возможность четкого определения требований, построения моделей и их последовательной проверки. Такая организация позволяет агентам взаимодействовать, обмениваться информацией и совместно работать над сложными задачами, минимизируя ошибки и обеспечивая согласованность принимаемых решений. В отличие от более простых подходов, STAR обеспечивает формализованную структуру для организации мыслительного процесса, что особенно важно при решении комплексных задач, требующих высокой степени точности и надежности.
Архитектура STAR использует экспертную систему SCHEMA для обеспечения отслеживания требований и поддержания согласованности на протяжении всего процесса рассуждений. SCHEMA функционирует как централизованный репозиторий, где фиксируются все требования к решаемой задаче, промежуточные выводы и принятые решения. Это позволяет системе автоматически выявлять противоречия, неполноту информации и несоответствия между различными этапами рассуждений. Механизмы SCHEMA включают в себя валидацию данных, контроль версий требований и автоматическую генерацию отчетов о соответствии требованиям, что критически важно для обеспечения надежности и воспроизводимости результатов работы системы.

Валидация Агентного Рассуждения с Помощью RWS
Бенчмарк RWS (Reasoning with Steps) продемонстрировал существенные различия между подходами, основанными на агентах, и системами, полагающимися исключительно на большие языковые модели (LLM). Анализ выявил ограничения существующих бенчмарков, таких как HumanEval, GPQA и SWE-bench, в оценке способности к сложному рассуждению. В то время как LLM могут демонстрировать впечатляющие результаты в задачах, требующих запоминания и воспроизведения информации, они часто терпят неудачу при решении проблем, требующих последовательного применения логических шагов и глубокого понимания предметной области. RWS, в отличие от них, требует от систем не только получения ответа, но и предоставления четкой и обоснованной цепочки рассуждений, что позволяет более точно оценить их истинный потенциал в решении сложных задач.
Для обеспечения объективной и воспроизводимой оценки решений в рамках бенчмарка RWS, была разработана программная система проверки. Эта система не полагается на поверхностное сравнение текстовых ответов, а оценивает решения на основе символьной эквивалентности. Иными словами, она проверяет, приводят ли различные подходы к математически одинаковым результатам, даже если сами ответы представлены в разной форме. Такой подход позволяет избежать предвзятости, связанной с форматированием или стилем изложения, и гарантирует, что оценка отражает истинную способность системы к рассуждениям, а не просто её умение генерировать текст, похожий на человеческий. Использование символьной эквивалентности обеспечивает надежность и сопоставимость результатов, что особенно важно при сравнении различных подходов к решению сложных задач.
Проведенная валидация подтверждает способность агентных систем решать сложные задачи рассуждения в гелиофизике, которые в настоящее время недоступны для большинства больших языковых моделей. В ходе исследований было установлено, что все многоагентные стратегии демонстрируют превосходство над одношаговыми базовыми моделями, указывая на значительный потенциал координации между агентами для достижения более высоких результатов. Это особенно важно, учитывая, что традиционные бенчмарки, такие как HumanEval и GPQA, часто не способны адекватно оценить способности к сложному рассуждению, в то время как RWS (Reasoning with Symbols) обеспечивает более надежную и объективную оценку, основанную на символической эквивалентности решений.
Исследования показали, что различные стратегии координации между агентами демонстрируют выраженную эффективность в решении конкретных задач. В частности, система PACE достигла наивысшей точности в задачах GSM8K и MATH, ориентированных на математическое рассуждение, в то время как HMAW превзошла другие системы в решении задач GPQA, требующих понимания физических принципов. Система SCHEMA, напротив, показала лучшие результаты в задачах HumanEval, SWE-bench Verified и RWS, что свидетельствует о ее превосходстве в задачах, связанных с программированием и верификацией кода. Эти результаты подчеркивают, что выбор оптимальной стратегии координации между агентами имеет решающее значение для достижения высоких показателей в различных областях, и что универсального подхода к решению сложных задач не существует.
Будущие Направления: Масштабирование и Обобщение
Дальнейшие исследования сосредоточены на расширении масштабов агентивных систем для решения всё более сложных задач и разработке методов обобщения, позволяющих применять их в различных областях. Необходимость в увеличении вычислительных ресурсов и оптимизации алгоритмов становится критичной по мере усложнения решаемых проблем. Особое внимание уделяется созданию агентов, способных к адаптации и переносу знаний из одной области в другую, что предполагает разработку новых подходов к обучению с подкреплением и мета-обучению. Успешное масштабирование и обобщение позволят перейти от решения узкоспециализированных задач к созданию универсальных интеллектуальных систем, способных к автономному обучению и решению проблем в широком спектре дисциплин.
Исследования новых архитектур агентов и протоколов коммуникации представляются ключевыми для повышения эффективности и устойчивости подобных систем. Разработка более гибких и адаптивных структур позволит агентам эффективно взаимодействовать в сложных средах, обмениваясь информацией и координируя действия для достижения общих целей. Особое внимание уделяется разработке протоколов, позволяющих агентам не только передавать данные, но и понимать намерения друг друга, что значительно улучшит качество совместной работы и позволит преодолевать неопределенность в динамично меняющихся условиях. Подобные усовершенствования позволят создавать более надежные и производительные системы, способные решать широкий спектр задач в различных областях, от научных исследований до автоматизации производственных процессов.
Успех системы RWS ярко демонстрирует потенциал рассуждений, основанных на взаимодействии агентов, для коренной трансформации подхода к решению задач в научных областях и за их пределами. Данная архитектура открывает путь к созданию действительно интеллектуальных систем, способных к самостоятельному анализу, планированию и выполнению сложных действий. Особенностью является возможность разбиения масштабных проблем на более мелкие, решаемые независимыми агентами, что повышает эффективность и масштабируемость решения. Этот подход позволяет не только автоматизировать научные исследования, но и создавать системы, способные адаптироваться к новым задачам и обучаться на собственном опыте, приближая нас к созданию искусственного интеллекта нового поколения.
Представленная работа подчеркивает важность четкой постановки задачи перед любым вычислительным процессом. Без точного определения цели, любое решение, каким бы сложным оно ни было, представляет собой лишь шум. Исследование демонстрирует, что даже сложные системы, такие как многоагентные системы, не могут эффективно решать задачи гелиофизики без ясной формулировки вопроса. Как однажды заметила Грейс Хоппер: «Лучший способ объяснить что-то — это сначала объяснить, что это не такое». Эта фраза прекрасно иллюстрирует необходимость точного определения задачи, прежде чем пытаться ее решить, особенно в контексте сложных научных исследований, представленных в данной работе.
Куда Далее?
Представленная работа, хотя и демонстрирует потенциал многоагентных систем в задаче научного рассуждения, не решает, а лишь подчеркивает фундаментальную сложность проблемы. Наблюдение о том, что не существует универсальной стратегии координации, не является неожиданным; скорее, это напоминание о том, что “оптимизация без анализа” — это самообман и ловушка для неосторожного разработчика. Истинная элегантность не в достижении наилучшего результата на конкретном наборе данных, а в создании системы, способной адаптироваться к непредсказуемости научного поиска.
Будущие исследования должны сосредоточиться не на создании “суперинтеллекта”, а на разработке формальных методов верификации и доказательства корректности алгоритмов рассуждения. Эмпирическая оценка, хоть и необходима, недостаточна; необходимы гарантии, что система не просто “работает на тестах”, но и способна к надежному выводу в новых, неизученных ситуациях. Необходимо углубиться в вопрос представления знаний в таких системах, поскольку поверхностное использование больших языковых моделей не является истинным решением.
Особый интерес представляет исследование взаимодействия между различными агентами, не только в контексте координации, но и в разрешении когнитивных диссонансов. Необходимо разработать механизмы, позволяющие агентам критически оценивать информацию, поступающую от других агентов, и выявлять потенциальные ошибки или предвзятости. В конечном счете, истинный прогресс в области научного рассуждения требует не просто создания более мощных алгоритмов, а развития более глубокого понимания самой природы научного познания.
Оригинал статьи: https://arxiv.org/pdf/2511.20694.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовая обработка данных: новый подход к повышению точности моделей
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Квантовый Переход: Пора Заботиться о Криптографии
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовые симуляторы: проверка на прочность
- Квантовые прорывы: Хорошее, плохое и смешное
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Квантовая химия: моделирование сложных молекул на пороге реальности
2025-11-27 13:33