Автор: Денис Аветисян
Новый подход позволяет значительно повысить эффективность работы больших языковых моделей, не жертвуя качеством рассуждений.
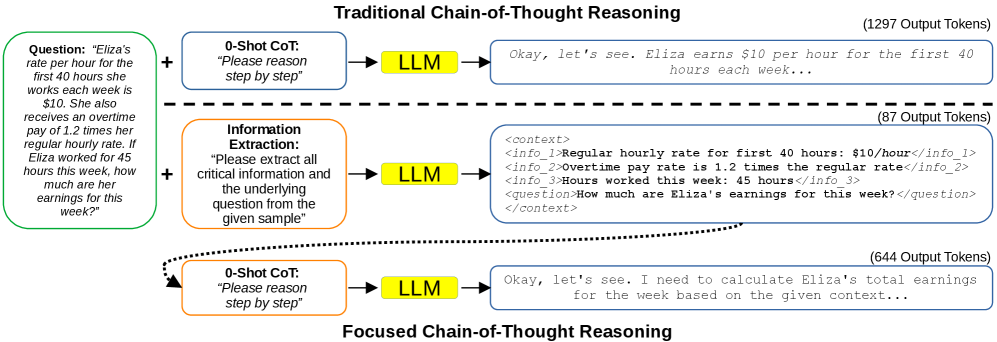
Предлагается метод Focused Chain-of-Thought (F-CoT), отделяющий извлечение информации от этапа рассуждений, что приводит к снижению использования токенов в 2-3 раза.
Несмотря на впечатляющие возможности современных больших языковых моделей (LLM) в решении задач рассуждения, их эффективность часто снижается из-за избыточного использования токенов и высокой задержки. В статье ‘Focused Chain-of-Thought: Efficient LLM Reasoning via Structured Input Information’ предложен новый подход, Focused Chain-of-Thought (F-CoT), который разделяет процесс извлечения информации и последующего рассуждения. F-CoT позволяет значительно сократить количество генерируемых токенов — в 2-3 раза — при сохранении точности решений. Может ли структурирование входных данных стать ключевым фактором повышения эффективности и масштабируемости LLM в сложных задачах рассуждения?
За пределами масштаба: Рассуждения, не сводящиеся к предсказанию
Языковые модели большого размера демонстрируют впечатляющую способность распознавать закономерности в данных, что позволяет им успешно выполнять задачи, связанные с предсказанием следующего слова или фразы. Однако, когда требуется последовательное применение логических операций и многоступенчатое рассуждение, их производительность существенно снижается. Модели часто испытывают трудности с задачами, требующими анализа информации, построения логических связей и вывода новых знаний, поскольку их обучение в основном сосредоточено на статистических корреляциях, а не на глубоком понимании причинно-следственных связей. Это проявляется в неспособности решать сложные головоломки, проводить научные исследования или эффективно планировать действия в динамичной среде, подчеркивая ограничения существующих подходов к искусственному интеллекту в области сложного мышления.
Исследования показывают, что простое увеличение масштаба языковых моделей не приводит к пропорциональному улучшению их способности к рассуждению. Напротив, модели, обученные на огромных объемах данных, часто демонстрируют склонность к так называемому “переосмыслению” — процессу, когда модель излишне усложняет задачу, генерируя избыточные и неэффективные вычислительные шаги. Вместо того чтобы прийти к прямому и логичному решению, модель может зацикливаться на второстепенных деталях или генерировать длинные цепочки рассуждений, которые в конечном итоге не приводят к правильному ответу. Это указывает на то, что улучшение способности к рассуждению требует не только увеличения объема данных и вычислительных ресурсов, но и разработки новых архитектур и алгоритмов, которые позволяют моделям эффективно использовать имеющиеся ресурсы и избегать излишней сложности.
Современные методы стимулирования больших языковых моделей, такие как генерация с расширением извлечением и использование графов знаний, зачастую усложняют процесс, не решая фундаментальных проблем с логическим мышлением. Хотя эти подходы направлены на предоставление моделям дополнительной информации и структурированных данных, исследования показывают, что они не всегда приводят к улучшению способности решать сложные задачи, требующие многоступенчатого рассуждения. Вместо того, чтобы устранять узкие места в логике, эти методы могут приводить к увеличению вычислительной нагрузки и усложнению интерпретации результатов, что в конечном итоге ограничивает возможности моделей в решении задач, выходящих за рамки простого распознавания паттернов. Таким образом, акцент смещается с простого увеличения объема данных и сложности архитектуры на разработку более эффективных алгоритмов, способных к действительному логическому выводу.
Сфокусированная цепочка рассуждений: Когнитивная основа
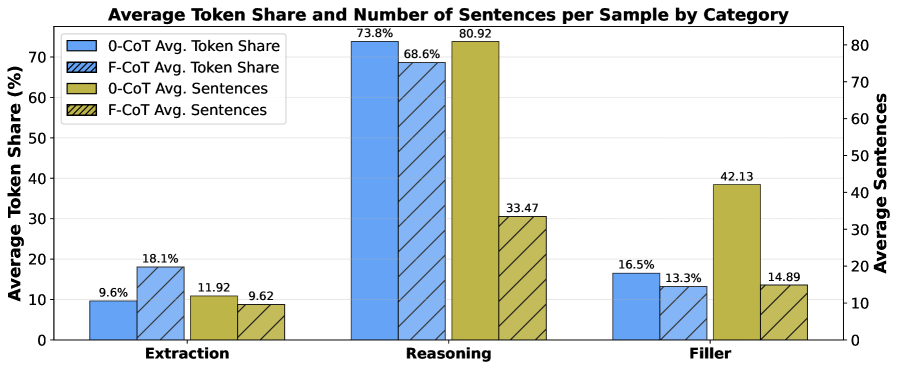
Метод Focused Chain-of-Thought (FCoT) основывается на принципах структуры Active Control of Thought (ACT), рассматривая процесс рассуждений как последовательность эффективных этапов обработки информации. В ACT, когнитивные ресурсы направляются на конкретные этапы решения задачи, что позволяет оптимизировать использование памяти и вычислительных ресурсов. FCoT адаптирует этот подход, моделируя рассуждения как серию четко определенных шагов, где каждый шаг направлен на извлечение, структурирование или обработку конкретных данных. Это позволяет отделить этапы предварительной обработки информации от этапов логического вывода, повышая эффективность и снижая избыточность в процессе решения задач.
В отличие от традиционного подхода Chain-of-Thought (CoT), Focused Chain-of-Thought (FCoT) разделяет этапы извлечения и структурирования информации от собственно процесса рассуждений. В CoT вся релевантная информация, включая промежуточные выводы, включается непосредственно в запрос, что приводит к избыточности и увеличению объема токенов. FCoT, напротив, предварительно обрабатывает входные данные, выделяя и структурируя ключевые факты, после чего передает только эту структурированную информацию для выполнения рассуждений. Такой подход позволяет избежать повторения информации и фокусироваться на логических выводах, значительно снижая количество токенов, необходимых для получения результата.
В рамках Focused Chain-of-Thought (FCoT) используется формат Context Block, по структуре напоминающий XML, для представления предварительно обработанной информации. Этот подход позволяет значительно сократить объем токенов, необходимых для передачи контекста модели, обеспечивая уменьшение в 2-3 раза по сравнению со стандартными методами промптинга. Компактное представление данных достигается за счет структурированного формата, исключающего избыточность и фокусирующегося на релевантной информации, что повышает эффективность использования ресурсов и снижает стоимость обработки запросов.
Проверка и производительность: Точность в сочетании с эффективностью
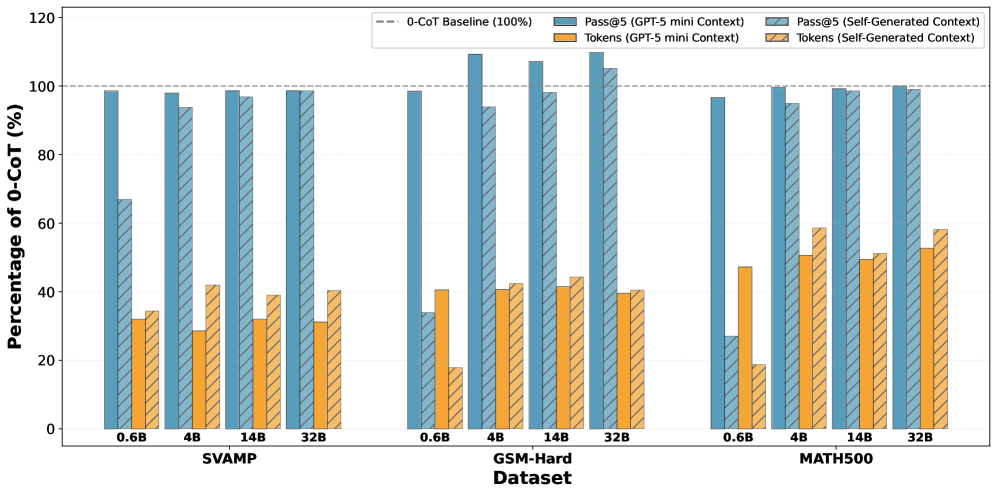
Метод FCoT демонстрирует повышенную точность рассуждений, достигая показателя в 99.2% Pass@5 на датасете MATH-500 при использовании модели Qwen3 14B. Этот показатель Pass@5 означает, что из пяти предложенных вариантов решения, правильный ответ был найден в 99.2% случаев. Оценка проводилась на наборе математических задач MATH-500, предназначенном для оценки способностей моделей к решению сложных математических задач, требующих логических выводов и рассуждений.
Метод FCoT, за счет минимизации потребления токенов, обеспечивает возможность масштабирования во время тестирования (Test-Time Scaling). Это позволяет перераспределять доступные вычислительные ресурсы и время на этап инференса, увеличивая продолжительность обработки каждого запроса. В результате, при сохранении количества использованных токенов, можно добиться повышения точности и производительности модели без увеличения аппаратных затрат. Фактически, FCoT позволяет эффективно использовать существующие ресурсы для улучшения качества получаемых результатов, особенно в задачах, требующих сложного логического вывода.
Эксперименты показали, что FCoT эффективно обходит ограничения, свойственные обучению с подкреплением (Reinforcement Learning), которое часто испытывает трудности при решении сложных задач, требующих логических рассуждений. В то время как методы обучения с подкреплением могут сталкиваться с проблемами масштабируемости и нестабильности при работе с многоступенчатыми процессами вывода, FCoT демонстрирует стабильную производительность и эффективность в задачах, требующих глубокого анализа и последовательного применения логических правил. Это связано с тем, что FCoT не требует процесса обучения с подкреплением, а использует предобученную языковую модель для генерации рассуждений, что позволяет избежать проблем, связанных с определением функции вознаграждения и оптимизацией стратегии обучения.
За горизонтом текущих ограничений: Влияние и перспективы
Принципы FCoT демонстрируют свою универсальность, позволяя значительно улучшить производительность различных больших языковых моделей (LLM) посредством простой корректировки запросов, или «промптинга». Вместо дорогостоящего и трудоемкого переобучения моделей, FCoT предлагает экономически эффективный путь к раскрытию их потенциала. Этот подход позволяет максимально использовать существующие ресурсы, не требуя значительных инвестиций в вычислительные мощности или разработку. Это особенно актуально для организаций, стремящихся внедрить передовые технологии обработки естественного языка без значительных финансовых затрат, делая FCoT практичным решением для широкого круга применений и обеспечивая гибкость в адаптации к быстро меняющимся требованиям.
Применение модели GPT-5 Mini для предварительного вычисления контекста значительно повышает эффективность процесса рассуждений и позволяет решать более сложные задачи. Этот подход позволяет разложить сложную проблему на более мелкие, управляемые части, которые GPT-5 Mini обрабатывает заранее, предоставляя основной модели уже структурированную и релевантную информацию. В результате снижается нагрузка на основную языковую модель, ускоряется процесс получения ответа и повышается его точность, особенно в случаях, когда требуется анализ большого объема данных или выполнение многоступенчатых логических операций. Предварительное вычисление контекста открывает возможности для решения задач, которые ранее были недоступны из-за ограничений вычислительных ресурсов или сложности рассуждений.
В ходе экспериментов с моделью Qwen3 14B, методика FCoT продемонстрировала значительное снижение потребности в токенах для достижения сопоставимых результатов. Вместо 4.2 тысяч токенов, необходимых для стандартного подхода 0-CoT, FCoT успешно справляется с задачей, используя всего 3.1 тысячу токенов. Это уменьшение объема используемых данных не только снижает вычислительные затраты и ускоряет процесс обработки, но и открывает возможности для работы с более длинными контекстами и решения более сложных задач, где ограниченность токенов является критическим фактором. Такая эффективность делает FCoT перспективным инструментом для оптимизации работы больших языковых моделей и расширения их возможностей.
Исследование демонстрирует стремление к лаконичности и эффективности в работе с большими языковыми моделями. Авторы предлагают стратегию Focused Chain-of-Thought (F-CoT), отделяющую извлечение информации от процесса рассуждений. Этот подход позволяет значительно сократить количество токенов, используемых моделью, при сохранении качества логических выводов. Как однажды заметил Джон фон Нейманн: «В науке не бывает окончательных ответов, только лучшие приближения». Данная работа — ещё одно приближение к оптимальному использованию ресурсов при решении сложных задач, демонстрируя, что ясность и простота могут быть ключом к повышению эффективности даже в самых передовых технологиях. Отказ от избыточности в представлении информации — это не упрощение, а осознанный выбор в пользу более элегантного и действенного решения.
Что Дальше?
Представленный подход, отделяющий извлечение информации от логических построений, обнажает фундаментальную неэффективность, присущую современным большим языковым моделям. Необходимость обрабатывать избыточный контекст — это не просто техническая проблема, это признание неспособности модели к истинному пониманию. Уменьшение количества токенов — это не самоцель, а лишь симптом более глубокой болезни: переоценки количества в ущерб качеству.
Настоящая работа не решает проблему, а лишь указывает на её корень. Следующим шагом представляется не поиск более изощренных методов “подсказок”, а разработка архитектур, способных к более компактному представлению знаний. Модель, требующая длинных инструкций для выполнения элементарных рассуждений, уже проиграла. Вместо того, чтобы “кормить” модель все большим количеством данных, следует сосредоточиться на создании моделей, которые могут учиться по сути, а не по объему.
Истинно полезный прогресс в этой области будет заключаться не в увеличении масштаба, а в уменьшении сложности. Стремление к ясности — это не просто эстетический выбор, это необходимость. Понятность — это вежливость, и в конечном итоге — это признак истинного интеллекта. Иначе мы рискуем построить великолепные, но бессмысленные конструкции, которые в конечном итоге рухнут под собственным весом.
Оригинал статьи: https://arxiv.org/pdf/2511.22176.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-12-01 16:40