Автор: Денис Аветисян
Новый метод позволяет эффективно моделировать взаимодействие между принципалом и агентом в условиях высокой неопределенности и сложных ограничений.
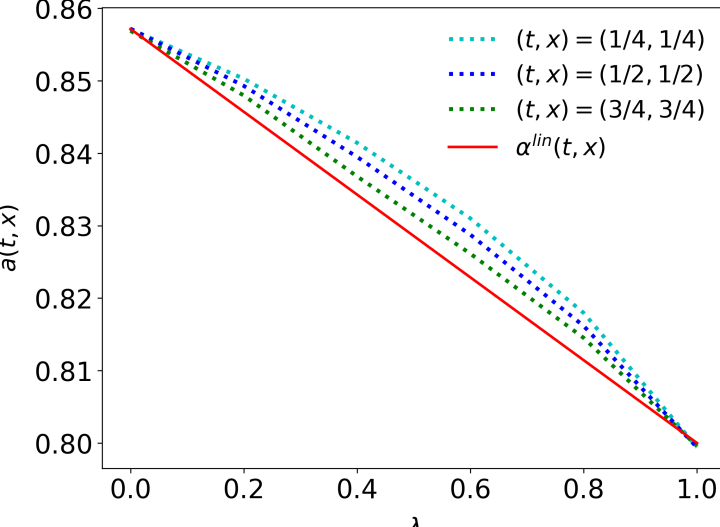
В статье представлен алгоритм DeepPAAC – метод глубокого обучения на основе Galerkin, предназначенный для решения непрерывно-временных задач теории агентства с многомерными состояниями, управлением и ограничениями.
Несмотря на широкое применение теории агентских отношений, эффективное численное решение соответствующих задач в условиях непрерывного времени остается сложной задачей. В статье ‘DeepPAAC: A New Deep Galerkin Method for Principal-Agent Problems’ предложен новый метод, DeepPAAC, основанный на глубоком обучении и алгоритме «актер-критик», для решения задач «принципал-агент» с многомерными стратегиями и ограничениями. Разработанный подход позволяет эффективно аппроксимировать решения уравнений Гамильтона-Якоби-Беллмана, демонстрируя сходимость и эффективность на нескольких модельных примерах. Какие перспективы открывает применение данного метода для анализа более сложных и реалистичных моделей агентских отношений в различных областях?
Стратегическое Взаимодействие: Суть Проблемы Принципала и Агента
Многие реальные сценарии включают в себя делегирование задач. Эффективное моделирование этих взаимодействий требует понимания проблемы управления агентом и целей принципала. Успешное решение предполагает разработку механизмов, стимулирующих агента к действиям, соответствующим интересам принципала, посредством оптимальных контрактов и систем вознаграждений, учитывающих информационную асимметрию. Неизбежная сложность требует надежных математических инструментов для анализа и прогнозирования поведения таких систем. Иногда, истинное мастерство проявляется не в усложнении, а в предельном упрощении.
Динамика во Времени и Уравнение Гамильтона-Якоби-Беллмана
Формулирование проблемы в непрерывном времени позволяет более реалистично отразить текущие взаимодействия. Такой подход учитывает динамику отношений, в отличие от статических моделей, что важно при анализе долгосрочных контрактов. Это приводит к задаче динамического программирования, управляемой уравнением Гамильтона-Якоби-Беллмана (HJB), описывающим эволюцию оптимальной стратегии агента. Однако, аналитическое решение часто невозможно, требуя сложных вычислительных методов, таких как численные схемы, методы Монте-Карло и алгоритмы машинного обучения для аппроксимации.
Глубокие Галеркин: Решение через Нейронные Сети
Метод глубоких Галеркина (DGM) использует глубокие нейронные сети для аппроксимации решения уравнения HJB, позволяя найти приближенное решение без явного построения сетки. Исходная задача рассматривается как задача аппроксимации функции. Преобразование уравнения в задачу оптимизации позволяет использовать градиентные методы для вычисления решения, упрощая процесс и повышая эффективность. Таким образом, DGM представляет собой альтернативный подход, обходящий ограничения традиционных методов численного анализа.
Уточнение Стратегии: Схема «Актер-Критик»
Для оптимизации стратегии управления используется схема «Актер-Критик» в рамках DGM. Актер обучается оптимальной стратегии, а критик оценивает ее производительность, предоставляя обратную связь для улучшения. Это обеспечивает стабильное и быстрое обучение, позволяя системе адаптироваться к сложным условиям. Алгоритм DeepPAAC демонстрирует сходимость в пределах 51570-92580 итераций для различных примеров. Эффективность системы определяется не количеством параметров, а способностью к их лаконичному выражению.
Расширение Модели: Неприятие Риска и Ограниченное Управление
Включение неприятия риска в предпочтения агента добавляет модели реалистичности, позволяя адекватно отразить поведение агента в условиях неопределенности. Предложенная структура расширяется до задач с ограничением управления путем включения штрафных функций или ограничений в целевую функцию. Эти расширения расширяют применимость подхода к более широкому спектру взаимодействий, прокладывая путь к более тонким и практичным решениям. Моделирование неприятия риска и ограничений действий делает данный фреймворк полезным для разработки систем искусственного интеллекта.
Представленная работа демонстрирует стремление к элегантности в решении сложных задач, что находит отклик в словах Пьера Кюри: “Я верю, что наука должна быть служанкой человечества.” Исследование, посвященное методу DeepPAAC, показывает, как глубокое обучение может быть использовано для эффективного решения задач Principal-Agent с многомерными характеристиками. Как и в научном поиске, где требуется отсеять лишнее для достижения ясности, DeepPAAC стремится к упрощению сложных вычислений, предлагая элегантный подход к анализу моделей Principal-Agent, и раскрывая потенциал для более реалистичных и комплексных исследований в этой области. Удаление избыточности в коде, подобно удалению ненужных компонентов в модели, ведет к более эффективному и понятному решению.
Что дальше?
Представленный метод, хотя и демонстрирует способность справляться со сложностями, присущими моделям «принципал-агент», не устраняет фундаментальную проблему: приближение непрерывного времени дискретными алгоритмами. Упрощение, неизбежное в реализации, всегда оставляет тень искажения. Истина, как и оптимальная стратегия, ускользает в бесконечно малом. Важно осознавать, что эффективность решения – это не столько достижение абсолютной точности, сколько умение найти баланс между сложностью модели и вычислительной целесообразностью.
Дальнейшие исследования, вероятно, сосредоточатся на преодолении этого ограничения. Использование более совершенных схем численного интегрирования, адаптивных сеток, или, возможно, даже разработка принципиально новых подходов к решению уравнения Гамильтона-Якоби-Беллмана, представляются наиболее перспективными направлениями. Но истинный прогресс, возможно, лежит не в усложнении, а в осознании границ применимости подобных моделей.
В конечном итоге, ценность любого метода определяется не его способностью решать сложные задачи, а его способностью выявлять и устранять ненужные сложности. Задача состоит не в том, чтобы создать идеальную модель, а в том, чтобы создать достаточно простую модель, способную отразить суть явления. И в этом поиске простоты кроется истинная сложность.
Оригинал статьи: https://arxiv.org/pdf/2511.04309.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-11-10 01:24