Автор: Денис Аветисян
Исследователи представили V-RGBX — систему, позволяющую редактировать видео с беспрецедентной точностью, манипулируя такими параметрами, как цвет, освещение и текстура.

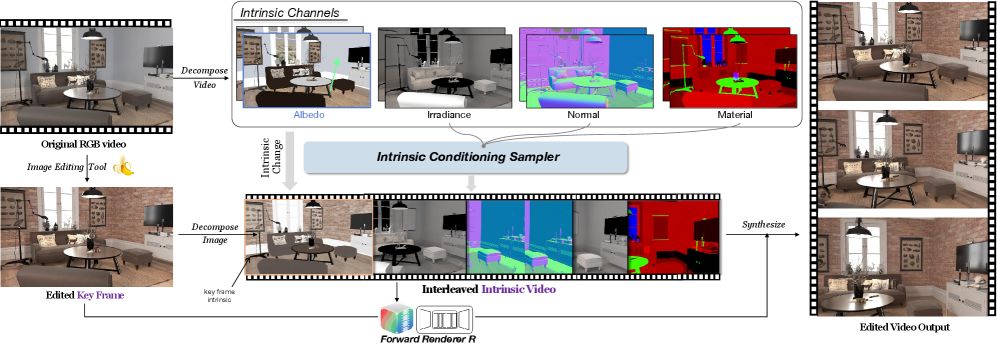
Предложен фреймворк V-RGBX, использующий разложение на внутренние компоненты изображения и генеративные модели для точного и согласованного редактирования видео.
Несмотря на значительный прогресс в генерации и редактировании видео, точное управление внутренними свойствами сцены, такими как альбедо, нормали и освещение, остается сложной задачей. В данной работе представлена система V-RGBX: Video Editing with Accurate Controls over Intrinsic Properties, — первая сквозная система для видеоредактирования с учетом внутренних характеристик. V-RGBX объединяет обратное рендеринг видео в каналы внутренних свойств, фотореалистичный синтез видео из этих представлений и редактирование на основе ключевых кадров, управляемое внутренними характеристиками. Сможет ли подобный подход открыть новые возможности для создания и манипулирования видеоконтентом с беспрецедентным уровнем контроля и реалистичности?
Преодолевая Границы RGB: Ограничения Традиционного Видеомонтажа
Традиционное видеомонтирование, основанное на непосредственной обработке RGB-кадров, оперирует исключительно цветовой информацией, игнорируя семантическое содержание изображения. Этот подход, по сути, представляет собой манипуляцию пикселями без понимания того, что эти пиксели представляют — например, поверхность материала, источник света или форму объекта. В результате, даже незначительные изменения, такие как корректировка цвета или применение фильтров, могут приводить к появлению артефактов, искажению текстур и неестественному виду итогового видео. Отсутствие семантической осведомленности означает, что программа не «знает», что редактируется, и поэтому не способна предвидеть или предотвратить эти нежелательные последствия, ограничивая возможности точного и реалистичного монтажа.
Традиционный подход к редактированию видео, основанный на непосредственной манипуляции с RGB-кадрами, часто сталкивается с трудностями при внесении сложных изменений и поддержании визуальной согласованности между кадрами. Особенно проблематичными оказываются ситуации, связанные с корректировкой освещения или свойств материалов. Незначительное изменение одного параметра, например, интенсивности света, может потребовать трудоемкой ручной корректировки во всех последующих кадрах, чтобы избежать заметных визуальных несоответствий. Попытки автоматизировать этот процесс нередко приводят к появлению артефактов или неестественных переходов, поскольку алгоритмы не учитывают физические свойства сцены и сложность взаимодействия света с различными поверхностями. В результате, даже относительно небольшие изменения могут потребовать значительных усилий для достижения реалистичного и плавного видеоряда.
Существующие методы видеомонтажа зачастую оперируют исключительно с визуальными данными, не учитывая физические свойства сцены, что существенно ограничивает возможности реалистичной и управляемой манипуляции с видео. Вместо анализа материалов, освещения и геометрии объектов, большинство алгоритмов обрабатывают видео как набор пикселей, что приводит к артефактам при сложных изменениях. Например, при изменении угла освещения традиционные методы не могут корректно смоделировать взаимодействие света с поверхностями, в результате чего тени и блики выглядят неестественно. Неспособность восстановить базовые физические параметры сцены — такие как отражающая способность, шероховатость и преломление света — делает невозможным создание правдоподобных изменений в видеоматериале, ограничивая возможности для творческого редактирования и реалистичной визуализации.

V-RGBX: Внутренние Представления для Контролируемого Видеомонтажа
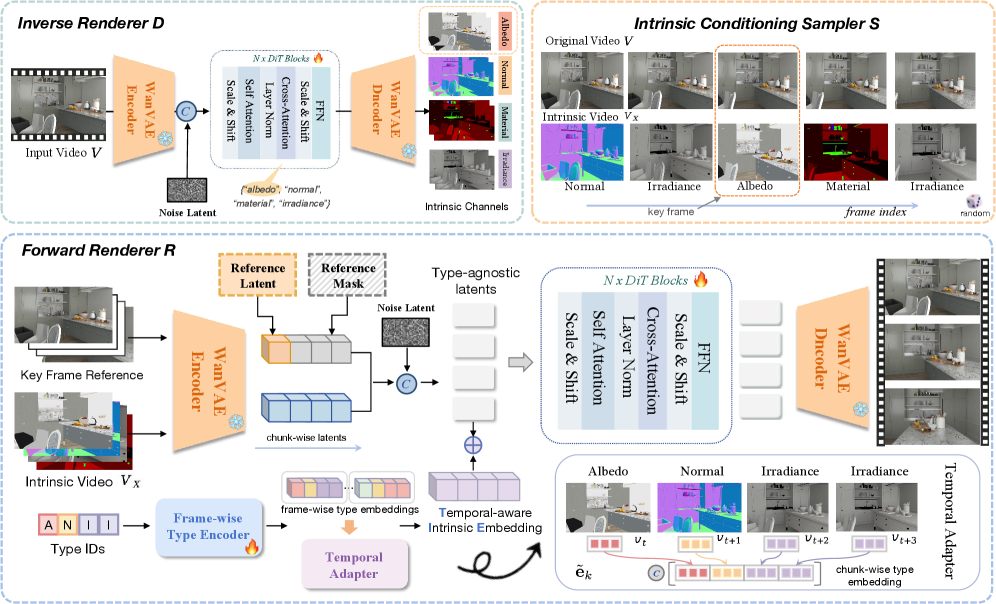
Метод V-RGBX осуществляет разложение видео на базовые внутренние представления, включающие в себя такие характеристики как альбедо, нормали поверхности, свойства материала и освещенность ($irradiance$). Альбедо описывает отражающую способность поверхности, определяя её цвет и яркость, в то время как нормали поверхности задают ориентацию каждой точки на объекте. Свойства материала характеризуют текстуру и взаимодействие поверхности со светом, а освещенность определяет интенсивность и направление светового потока. Разделение видео на эти компоненты позволяет манипулировать каждым свойством независимо, обеспечивая точный контроль над визуальными характеристиками сцены и реалистичное изменение видеоконтента.
Редактирование видео посредством манипулирования внутренними свойствами, такими как альбедо, нормали, материал и освещенность, позволяет вносить изменения на семантическом уровне. Вместо непосредственного изменения пикселей, модифицируются фундаментальные характеристики объектов и сцены, что обеспечивает физическую достоверность и согласованность результатов. Например, изменение материала объекта с матового на глянцевый влияет только на отражающие свойства, сохраняя геометрию и освещение неизменными. Этот подход предотвращает артефакты и несоответствия, возникающие при традиционных методах редактирования, обеспечивая реалистичность и правдоподобность финального видеоматериала.
В основе данной системы лежит использование диффузионных моделей как для обратного (inverse rendering), так и для прямого (forward rendering) рендеринга. Обратный рендеринг, основанный на диффузионной модели, позволяет реконструировать исходные параметры сцены — альбедо, нормали, материал и освещение — из входного видеопотока, обеспечивая высокую точность и детализацию. Затем, диффузионная модель для прямого рендеринга используется для генерации новых кадров видео на основе модифицированных параметров сцены. Такой подход позволяет осуществлять реалистичные изменения в видеоматериале, сохраняя при этом физическую правдоподобность и визуальную консистентность, поскольку процесс генерации кадров напрямую зависит от физических свойств реконструированной сцены.

Диффузионный Рендеринг: Сердце V-RGBX
В основе системы V-RGBX лежат модели Diffusion Transformer (DiT), используемые как для этапа обратного, так и для этапа прямого рендеринга. Архитектура DiT позволяет эффективно моделировать сложные зависимости в данных, необходимые для генерации реалистичных изображений и видео. В частности, DiT используется для восстановления исходных параметров сцены из входного изображения (обратный рендеринг) и для генерации новых изображений на основе модифицированных параметров (прямой рендеринг). Использование DiT обеспечивает высокую степень детализации и согласованности генерируемых кадров, что критически важно для создания качественного видеоконтента.
Процесс прямой визуализации в V-RGBX основан на архитектуре Weighted Average Noise (WAN), которая позволяет генерировать изображения путем усреднения зашумленных вариантов. Для повышения визуальной достоверности и детализации применяется техника Classifier-Free Guidance. Она заключается в обучении модели как с условными, так и с безусловными данными, что позволяет контролировать степень влияния условий (например, изменения внутренних свойств объекта) на итоговое изображение. Это позволяет получать более реалистичные и четкие кадры видео, особенно при манипулировании внутренними параметрами сцены.
Система V-RGBX использует диффузионные модели для генерации видеокадров высокого качества и обеспечения их временной согласованности на основе изменений внутренних свойств сцены. Изменяя такие параметры, как освещение, материалы или геометрия, система применяет обученную диффузионную модель для создания соответствующих изменений в результирующем изображении. Этот процесс позволяет V-RGBX генерировать реалистичные и визуально последовательные видео, в которых изменения происходят плавно и естественно, избегая артефактов и разрывов во времени. В результате, манипуляции с внутренними свойствами сцены напрямую транслируются в правдоподобные изменения в визуальном представлении видеоряда.
Стабильная и Согласованная Генерация с Чередующимся Обусловливанием
В основе V-RGBX лежит инновационный подход — чередующееся обусловливание, которое объединяет обработанные и необработанные внутренние модальности видео. Этот метод позволяет системе поддерживать временную согласованность на протяжении всего видеоряда, что критически важно для создания реалистичного и плавного изображения. Вместо последовательной обработки каждого кадра, V-RGBX динамически переключается между информацией, полученной из исходного и отредактированного контента, обеспечивая тем самым непрерывность визуального потока и минимизируя появление артефактов или мерцания, часто возникающих при традиционных методах видеоредактирования. Такое чередующееся взаимодействие между модальностями позволяет системе более эффективно предсказывать и воссоздавать последовательные кадры, формируя связный и визуально приятный видеоматериал.
Метод, используемый в V-RGBX, позволяет добиться плавных переходов между кадрами видео и эффективно предотвращает появление мерцания или артефактов, которые часто возникают при традиционном видеомонтаже. В отличие от существующих подходов, где изменения в отдельных модальностях могут приводить к визуальным искажениям, данная техника обеспечивает согласованность между обработанными и необработанными элементами видеопотока. Это достигается за счет интерлированного обусловливания, которое поддерживает временную когерентность и гарантирует, что каждое изменение в видео выглядит естественно и непрерывно, что значительно улучшает общее качество восприятия и создает более реалистичное и плавное визуальное впечатление.
Результаты тестирования разработанной системы на синтетических наборах данных демонстрируют значительное улучшение ключевых показателей качества реконструкции видео. В частности, отмечается повышение значений $PSNR$ (пиковое отношение сигнал/шум), $SSIM$ (структурное сходство) и $LPIPS$ (восприятие разницы), что свидетельствует о более высокой точности воссоздания деталей и общей визуальной схожести с исходным видеоматериалом. Данные метрики, широко используемые для оценки качества изображений и видео, позволяют объективно сравнить предложенный подход с существующими методами, подтверждая его превосходство в обеспечении более реалистичного и визуально приятного результата. Улучшение по этим показателям указывает на способность системы эффективно минимизировать артефакты и шумы, обеспечивая более четкое и детализированное изображение.
Перспективы: За Пределами Редактирования — К Динамическому Пониманию Сцены
Внутренние представления, полученные в результате обучения модели V-RGBX, обладают значительным потенциалом для применения в различных областях, выходящих за рамки редактирования видео. В частности, эти представления могут быть использованы для реконструкции трехмерных сцен, позволяя создавать детализированные цифровые модели окружающего мира на основе визуальных данных. Более того, полученные знания способствуют развитию технологий виртуальной реальности, обеспечивая более реалистичное и интерактивное погружение пользователя в смоделированные среды. Способность V-RGBX к эффективному представлению и пониманию сцен позволяет создавать более убедительные и правдоподобные виртуальные миры, открывая новые возможности для развлечений, обучения и профессиональных приложений.
В дальнейшем планируется расширение возможностей V-RGBX за счет интеграции более сложных физических моделей, позволяющих учитывать взаимодействие объектов и среды в динамичных сценах. Исследователи намерены изучить применение разработанной системы для задач предсказания и генерации видео, где V-RGBX сможет не только воссоздавать существующие сцены, но и прогнозировать их развитие во времени. Такой подход открывает перспективы для создания реалистичных виртуальных сред, интеллектуальных систем наблюдения и автоматизированного контента, способных генерировать правдоподобные и разнообразные видеоролики, имитирующие реальные физические процессы.
Оценка с использованием метрики FVD продемонстрировала значительное улучшение качества и разнообразия генерируемых видео по сравнению с существующими методами. Данный результат указывает на перспективность V-RGBX в создании более реалистичных и захватывающих визуальных впечатлений. В частности, метрика FVD, оценивающая сходство генерируемых кадров с реальными, показала, что V-RGBX способен производить видео, визуально более правдоподобные и отличающиеся большей вариативностью в деталях, что является ключевым фактором для создания убедительных виртуальных сцен и интерактивных приложений. Такое повышение качества открывает новые возможности для использования технологии в различных областях, включая развлечения, образование и научные исследования.

Представленная работа демонстрирует стремление к математической чистоте в области редактирования видео. Авторы, подобно тем, кто ищет элегантность в коде, стремятся к точному контролю над внутренними свойствами изображения — освещением, материалами и отражающей способностью. Это соответствует принципу, что любое решение должно быть корректным, а не просто «работать на тестах». В основе подхода V-RGBX лежит декомпозиция изображения на внутренние компоненты, позволяющая редактировать их независимо и последовательно. Как отметил Ян Лекун: «Машинное обучение — это математика, а не магия». Эта фраза подчеркивает необходимость строгого, основанного на принципах подхода к разработке алгоритмов, что и демонстрируется в данном исследовании, где каждый шаг логически обоснован и направлен на достижение предсказуемого и корректного результата.
Куда Далее?
Представленная работа, несомненно, открывает новые горизонты в области редактирования видео, однако следует помнить, что «управление свойствами» — это лишь половина дела. Истинная проблема заключается в построении моделей, способных к обоснованному изменению этих свойств. Простая манипуляция параметрами, без глубокого понимания физических процессов, лежащих в основе формирования изображения, — это, в лучшем случае, иллюзия контроля. Оптимизация без анализа, как известно, — самообман и ловушка для неосторожного разработчика.
Дальнейшие исследования должны быть направлены на интеграцию принципов физически корректного рендеринга непосредственно в архитектуру генеративных моделей. Необходимо отойти от эмпирических подходов к моделированию освещения и материалов, и стремиться к созданию систем, основанных на строгих математических принципах. Особое внимание следует уделить вопросам устойчивости и обобщающей способности — предложенные методы должны демонстрировать надежные результаты на разнообразных видеоданных, а не только на тщательно подобранных тестовых примерах.
В конечном счете, цель не в том, чтобы создать еще один инструмент для редактирования видео, а в том, чтобы построить систему, способную к пониманию и синтезу визуальной информации на принципиально новом уровне. И тогда, возможно, мы сможем говорить о действительно интеллектуальном редактировании видео.
Оригинал статьи: https://arxiv.org/pdf/2512.11799.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Кванты в Финансах: Не Шутка!
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Квантовый оптимизатор: Новый подход к сложным задачам
- Эволюция инструментов мышления: новый подход к научным открытиям
- От принципов к практике: как сделать данные по-настоящему взаимосовместимыми
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Оптимизация Комбинаторных Задач: Новый Взгляд с Помощью Автокодировщиков
2025-12-15 19:05