Автор: Денис Аветисян
Исследователи предлагают инновационную систему, объединяющую визуальное конструирование и языковые модели для улучшения логического мышления и решения математических задач.

Представлен фреймворк FigR, использующий обучение с подкреплением для интеграции визуальной конструкции в процесс рассуждений больших языковых моделей.
Сложные задачи рассуждения часто требуют учета неявных пространственных и структурных связей, которые трудно выразить в текстовой форме. В работе ‘Figure It Out: Improving the Frontier of Reasoning with Active Visual Thinking’ представлена новая методика FIGR, интегрирующая активное визуальное мышление в многошаговый процесс рассуждений посредством обучения с подкреплением. FIGR позволяет модели конструировать визуальные представления в процессе решения задач, что повышает стабильность и согласованность рассуждений, особенно в случаях, когда трудно уловить глобальные структурные закономерности из текста. Сможет ли подобный подход расширить границы возможностей языковых моделей в решении сложных математических задач и других областях, требующих визуально-пространственного мышления?
Пределы Текстового Мышления: Узкое Горлышко Рассуждений
Современные большие языковые модели, активно использующие текстовое рассуждение типа «Цепочка Мыслей» (Chain-of-Thought), демонстрируют значительные трудности при решении задач, требующих понимания пространственных или геометрических отношений. Несмотря на впечатляющие успехи в обработке и генерации текста, эти модели зачастую не способны адекватно представить и манипулировать визуальной информацией, необходимой для решения сложных математических задач или анализа пространственных конфигураций. В то время как текст позволяет последовательно излагать логические шаги, он оказывается недостаточным для кодирования и обработки информации, закодированной в визуальных образах, что приводит к ошибкам и неточностям в рассуждениях, особенно когда требуется оперировать с формами, размерами и взаимным расположением объектов. Данное ограничение подчеркивает необходимость разработки новых подходов, интегрирующих визуальное восприятие и пространственное рассуждение в архитектуру больших языковых моделей.
Традиционные методы рассуждений, основанные исключительно на текстовых цепочках умозаключений (Text-only CoT), зачастую демонстрируют неспособность адекватно представить и оперировать визуальной информацией, что критически важно при решении сложных математических задач. В то время как текстовые модели превосходно справляются с лингвистическим анализом, они испытывают трудности с пониманием геометрических отношений, пространственного расположения объектов и визуализацией математических концепций. Это приводит к ошибкам в задачах, требующих, например, вычисления площади, объема или определения взаимного расположения фигур на плоскости. Неспособность эффективно интегрировать визуальные данные ограничивает возможности этих моделей в решении задач, где визуальное восприятие является неотъемлемой частью процесса рассуждения, и подчеркивает необходимость разработки более совершенных подходов, способных полноценно использовать как текстовую, так и визуальную информацию.
Существующие мультимодальные подходы, такие как «Унифицированный Мультимодальный CoT» и «LVLMs, дополненные инструментами», стремятся преодолеть ограничения текстового мышления, однако сталкиваются с проблемами неточной привязки визуальной информации к задачам и ограниченным спектром доступных операций. Несмотря на попытки объединить текстовые рассуждения с визуальными данными, часто возникает сложность в точной интерпретации изображений и корректном использовании извлеченной информации для решения сложных математических задач. В частности, не всегда удается установить четкую связь между визуальными элементами и соответствующими текстовыми представлениями, что приводит к ошибкам в рассуждениях и неверным ответам. Ограниченность функционала инструментов, используемых для анализа изображений, также препятствует полноценному использованию визуальной информации и снижает эффективность мультимодальных систем.
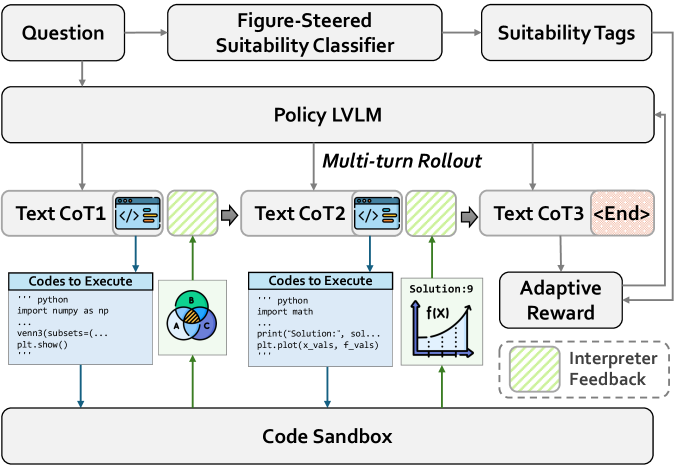
FigR: Визуальное Конструирование как Шаг Рассуждений
Метод FigR представляет собой новую разработку, использующую генерацию исполняемого кода для создания визуальных представлений в качестве неотъемлемой части процесса рассуждений. В отличие от традиционных подходов, где визуализация является отдельным шагом, FigR интегрирует создание визуализаций непосредственно в логическую цепочку. Это достигается путем динамической генерации кода, который производит визуальные элементы, необходимые для анализа и решения поставленной задачи. Генерируемый код может включать в себя инструкции для построения графиков, диаграмм или других визуальных представлений данных, позволяя модели не только обрабатывать информацию, но и активно формировать визуальный контекст для более эффективного рассуждения.
Метод FigR использует обучение с подкреплением (Reinforcement Learning) для определения оптимальных моментов и способов построения визуальных представлений в процессе рассуждений. В рамках этого подхода, агент обучается, когда и каким образом генерировать визуализации, которые наиболее эффективно дополняют и улучшают процесс логического вывода. Обучение происходит посредством максимизации вознаграждения, полученного в результате успешного использования визуализаций для решения поставленной задачи, что позволяет системе динамически адаптироваться и выбирать наиболее подходящие стратегии визуального конструирования.
Адаптивный механизм вознаграждения в процессе обучения с подкреплением позволяет `FigR` стратегически и эффективно применять визуальное рассуждение. Вознаграждение динамически изменяется в зависимости от текущего состояния рассуждения и сложности задачи. Изначально, модель получает более высокое вознаграждение за любое успешное использование визуальной конструкции, стимулируя ее исследование. По мере обучения, вознаграждение за визуализацию снижается для простых задач, где визуальное рассуждение не требуется, и повышается для сложных сценариев, требующих визуальных подсказок для принятия решений. Это позволяет модели оптимизировать частоту использования визуальных конструкций, избегая избыточных вычислений и фокусируясь на задачах, где визуальное рассуждение действительно повышает точность и эффективность.
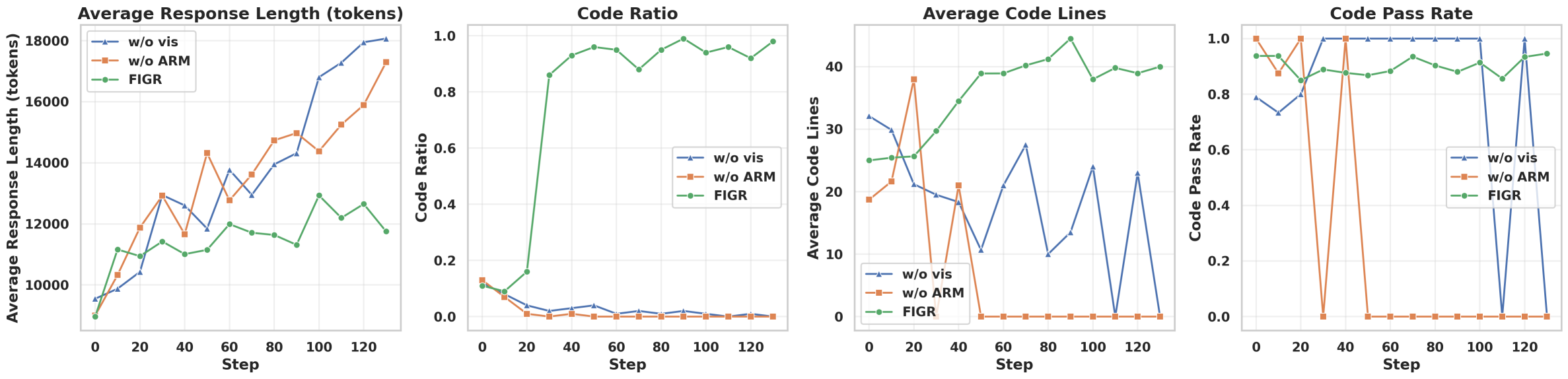
Проверка Эффективности FigR: Результаты на Разнообразных Наборах Данных
Модель FigR прошла обширное тестирование на наборе математических датасетов, включающем AIME, Beyond AIME, MATH 500, MinervaMath и OlympiadBench. Результаты показали превосходную производительность модели, с достижением средней точности в 73.45% по всем этим бенчмаркам. Данный показатель демонстрирует способность FigR эффективно решать широкий спектр математических задач различной сложности, представленных в указанных наборах данных.
Для подтверждения эффективности визуальной конструкции модели FigR использовались метрики `Code Ratio` и `Code Pass Rate`. `Code Ratio` показывает соотношение сгенерированного кода к общему количеству шагов решения, и FigR демонстрирует стабильно высокие значения этой метрики, указывающие на эффективное использование визуальных элементов в процессе решения задач. `Code Pass Rate` отражает процент успешно сгенерированных и проверенных фрагментов кода в процессе обучения, и FigR показал высокую пропускную способность кода во время тренировки, что свидетельствует о надежности и корректности генерируемых визуальных представлений и соответствующих фрагментов кода.
Модель FigR демонстрирует передовые результаты в решении математических задач, превосходя базовую модель Qwen3-VL-32B-Instruct на 6.90% по показателю точности. По сравнению с текстовой RL-базовой линией, FigR обеспечивает прирост точности в 4.81%. Данные результаты подтверждают эффективность предложенного подхода к визуальному построению решений и его превосходство над существующими методами, основанными исключительно на текстовой обработке.
В основе архитектуры FigR лежит большая мультимодальная модель Qwen3-VL-32B-Instruct, предобученная для обработки визуальной информации и текста. Для адаптации к решению математических задач и повышения производительности, модель была дополнительно обучена на специализированном датасете DeepMath-103K, содержащем 103 тысячи примеров математических задач. Использование Qwen3-VL-32B-Instruct в качестве базовой модели обеспечивает FigR широкие возможности по пониманию и интерпретации визуальных представлений математических выражений, а обучение на DeepMath-103K позволяет добиться высокой точности в решении различных математических задач.

За Пределами Математики: Влияние на Общие Способности Рассуждений
Успех модели FigR убедительно демонстрирует важность мультимодального мышления, указывая на то, что включение визуальных сигналов способно значительно расширить возможности искусственного интеллекта. Вместо того чтобы полагаться исключительно на символьные или числовые данные, FigR успешно объединяет текстовую информацию с геометрическими представлениями, позволяя ей решать задачи, требующие понимания как языка, так и визуальной логики. Этот подход открывает перспективы для создания более гибких и эффективных систем ИИ, способных обрабатывать информацию из различных источников и адаптироваться к сложным реальным условиям, где визуальные данные часто являются неотъемлемой частью процесса принятия решений. В частности, способность модели интегрировать визуальные подсказки позволяет ей более точно интерпретировать задачи и избегать ошибок, возникающих при обработке только текстовой информации.
Обеспечение геометрической согласованности является ключевым аспектом надежности визуальных представлений в системах искусственного интеллекта. В рамках данной работы, интеграция принципов геометрической согласованности в процесс рассуждений позволяет модели не просто «видеть» изображения, но и понимать их пространственные взаимосвязи. Это достигается путем проверки соответствия визуальных элементов базовым геометрическим правилам и принципам перспективы, что минимизирует ошибки, возникающие из-за неточностей или искажений в изображении. Такой подход позволяет системе не только распознавать объекты, но и делать обоснованные выводы об их положении, размере и взаимосвязи в пространстве, значительно повышая точность и достоверность визуального анализа и последующего принятия решений.
Принципы, лежащие в основе архитектуры FigR — динамическое построение визуальных представлений под управлением обучения с подкреплением — обладают значительным потенциалом для адаптации к широкому спектру областей, требующих пространственного или визуального понимания. Данный подход позволяет создавать системы, способные не просто распознавать изображения, но и активно конструировать и манипулировать визуальной информацией для решения сложных задач. В отличие от традиционных методов, полагающихся на статичные наборы данных, FigR демонстрирует способность к обучению в интерактивной среде, что открывает перспективы для применения в робототехнике, навигации, проектировании и даже в задачах, связанных с анализом данных, где визуализация играет ключевую роль. Способность модели динамически адаптировать свои визуальные представления позволяет ей эффективно справляться с неполной или неоднозначной информацией, что делает её особенно ценной в реальных условиях, где данные часто бывают зашумленными или неполными.
Механизм визуальной обратной связи, реализованный в модели, играет ключевую роль в оптимизации процесса рассуждений. Он позволяет системе не просто оперировать визуальной информацией, но и оценивать соответствие полученных результатов ожидаемым, корректируя дальнейшие шаги. В процессе обучения модель анализирует расхождения между сгенерированными визуальными представлениями и фактическими данными, используя эту информацию для улучшения своей стратегии рассуждений. Такой подход значительно повышает точность и эффективность решения задач, требующих пространственного понимания и визуального анализа, поскольку система способна самообучаться и адаптироваться к новым условиям, минимизируя ошибки и повышая надежность принимаемых решений. В результате, визуальная обратная связь становится неотъемлемой частью процесса обучения, позволяя модели достигать более высоких результатов в задачах, требующих комплексного визуального и логического мышления.
Представленная работа демонстрирует элегантный подход к решению задач визуального рассуждения, интегрируя процесс визуальной конструкции непосредственно в цикл рассуждений больших языковых моделей. Этот метод, основанный на обучении с подкреплением, позволяет не только повысить эффективность решения математических задач, но и сделать сам процесс более интерпретируемым. Как однажды заметил Г.Х. Харди: «Математика — это наука о бесконечности», и данное исследование, стремясь к более глубокому пониманию и представлению знаний, подтверждает эту мысль. Подход, реализованный в FigR, подчеркивает важность структурного анализа и построения логических связей, что является ключевым аспектом в математике и, шире, в научном познании.
Куда же дальше?
Представленная работа, несомненно, демонстрирует потенциал интеграции визуальной конструкции непосредственно в процесс рассуждений больших языковых моделей. Однако, подобно тщательно выстроенному архитектурному плану, она лишь очерчивает контуры более сложной структуры. Очевидно, что эффективность предложенного подхода, FigR, сильно зависит от качества визуальных представлений, создаваемых системой. Вопрос о том, как обеспечить согласованность и семантическую точность этих визуализаций, остается открытым. Особенно важно понять, как избежать создания визуальных «шумов», которые могут запутать модель и ухудшить её способность к решению задач.
Более того, существующая архитектура предполагает, что визуальное мышление универсально применимо ко всем типам математических задач. Однако, не исключено, что различные области математики требуют специфических стратегий визуализации. Дальнейшие исследования должны быть направлены на разработку адаптивных систем, способных динамически выбирать наиболее подходящие визуальные инструменты в зависимости от контекста задачи. В конечном итоге, истинный прогресс потребует отхода от простого добавления визуальных элементов к существующим моделям и перехода к разработке принципиально новых архитектур, в которых визуальное и языковое мышление будут неразрывно связаны.
Наконец, необходимо помнить, что элегантность решения определяется не только его функциональностью, но и его простотой. Стремление к чрезмерной сложности визуализаций может привести к обратному эффекту, затрудняя интерпретацию и снижая эффективность. Поиск оптимального баланса между выразительностью и простотой представляется ключевой задачей для будущего развития данной области.
Оригинал статьи: https://arxiv.org/pdf/2512.24297.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Квантовые нейросети на службе нефтегазовых месторождений
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Квантовая криптография: от теории к практике
- Робот, который видит, понимает и действует: новая эра общего назначения
- Лунный гелий-3: Охлаждение квантового будущего
- Квантовые сети для моделирования молекул: новый подход
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые прорывы: Хорошее, плохое и смешное
2026-01-01 16:38