Автор: Денис Аветисян
Новый подход позволяет гибко комбинировать визуальные элементы из видео и изображений, создавая сложные сцены по текстовому запросу.
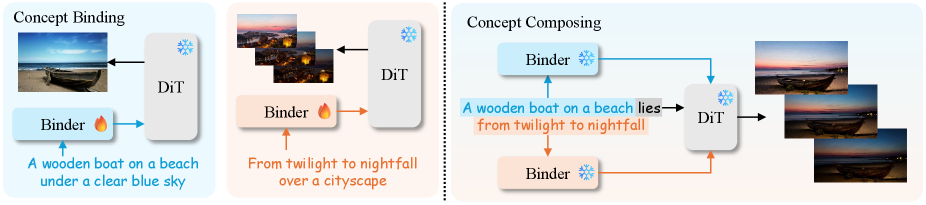
Представлен метод BiCo, использующий диффузионные модели и методы временного разделения для одношагового формирования визуальных концепций.
Несмотря на значительный прогресс в области генеративных моделей, точное и гибкое комбинирование визуальных концепций из изображений и видео остается сложной задачей. В статье ‘Composing Concepts from Images and Videos via Concept-prompt Binding’ предложен метод BiCo, обеспечивающий композицию визуальных концепций посредством привязки визуальных элементов к текстовым запросам и использования диффузионных моделей. Ключевым нововведением является иерархическая структура «binder» и стратегия временного разделения, позволяющие добиться высокой согласованности и качества генерируемого контента. Открывает ли BiCo новые горизонты для творческого использования мультимодальных данных и автоматизации создания видеоконтента?
Искусство Визуализации: Сложности и Перспективы
Создание высококачественного видео по текстовому описанию остается сложной задачей для современных систем искусственного интеллекта. Требуются модели, способные не просто визуализировать отдельные объекты, но и передавать нюансы смысла, сложные взаимосвязи и контекст, заключенные в тексте. Это подразумевает способность точно интерпретировать семантические детали, такие как эмоции, стиль и тон повествования, и преобразовывать их в визуально убедительное и последовательное видеоизображение. Достижение реалистичной и осмысленной визуализации требует от моделей глубокого понимания не только объектов, но и их взаимодействия в пространстве и времени, что значительно усложняет процесс генерации видеоконтента.
Существующие методы генерации изображений из текста зачастую испытывают трудности при создании сложных композиций, неспособных гармонично объединить несколько концепций в единую, визуально связную сцену. Эта проблема проявляется в несогласованности объектов, неестественных взаимосвязях между ними и общем ощущении фрагментированности изображения. Например, попытка сгенерировать сцену с «красным автомобилем, припаркованным возле высокой горы на фоне заката» может привести к изображению, где автомобиль выглядит оторванным от окружения, гора непропорциональна, а закат неестественен. Особенно остро эта проблема проявляется при увеличении количества объектов и усложнении их взаимосвязей, что ограничивает возможности создания реалистичных и убедительных визуальных представлений на основе текстового описания.
Для эффективного увеличения масштаба моделей, генерирующих видео из текста, необходимы архитектуры, обходящие традиционные вычислительные ограничения. Исследования показывают, что стандартные подходы часто сталкиваются с экспоненциальным ростом требуемых ресурсов при увеличении сложности сцены или продолжительности видео. Поэтому разрабатываются новые методы, такие как разреженные аттеншн-механизмы и каскадные генеративные сети, позволяющие сократить количество параметров и вычислительных операций без существенной потери качества. Эти архитектуры направлены на оптимизацию использования памяти и повышение скорости обработки, что критически важно для создания длинных и детализированных видеороликов с использованием искусственного интеллекта. В результате, более эффективные модели открывают возможности для более широкого применения технологии в различных областях, от развлечений до образования и научных исследований.

BiCo: Новая Стратегия Связывания для Визуального Синтеза
Метод BiCo реализует обучение в один проход (one-shot learning), позволяя эффективно комбинировать визуальные концепции посредством привязки к текстовым токенам. Это достигается за счет сопоставления визуальных элементов с конкретными текстовыми обозначениями, что позволяет модели синтезировать новые визуальные комбинации на основе ранее увиденных концепций без необходимости дополнительного обучения для каждой новой комбинации. Фактически, модель изучает соответствие между визуальным представлением и текстовым описанием, а затем использует это соответствие для генерации новых изображений или видео, комбинируя текстовые токены, представляющие различные визуальные элементы. Этот подход значительно повышает эффективность обучения и позволяет модели быстро адаптироваться к новым визуальным задачам.
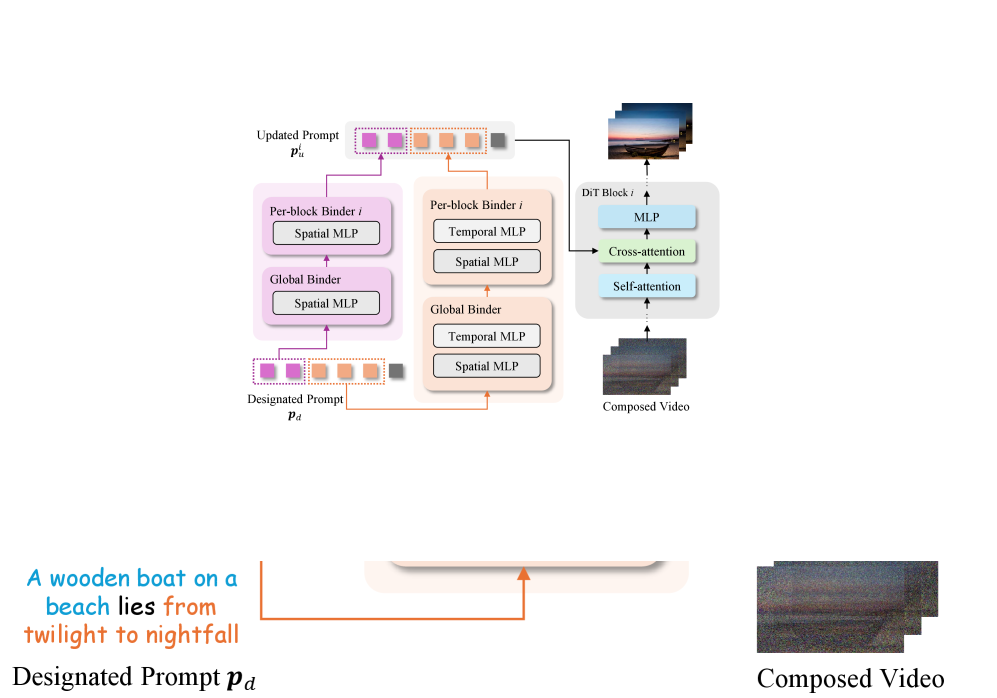
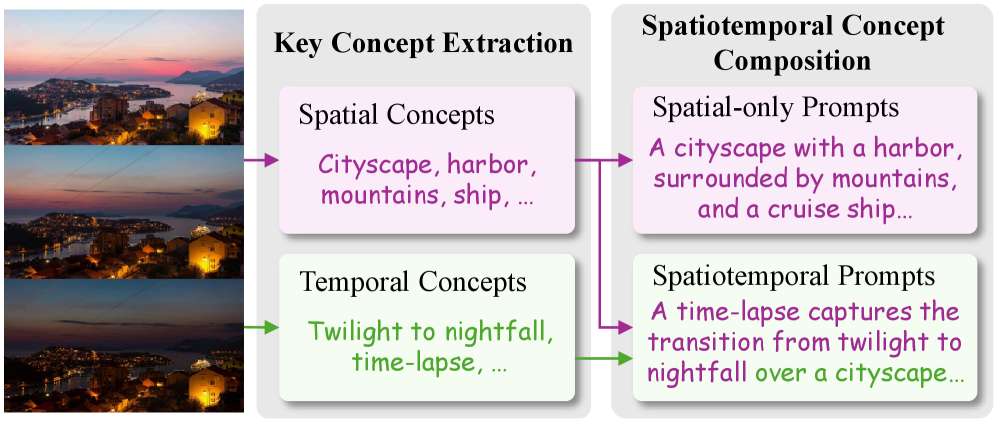
Иерархическая структура связывания (Hierarchical Binder Structure) в BiCo обеспечивает кодирование визуальных концепций в текстовое представление, понятное модели. Эта структура позволяет преобразовывать сложные визуальные элементы в последовательность токенов, что облегчает их интеграцию в процесс генерации видео. В частности, визуальные признаки извлекаются и организуются в иерархическом порядке, отражающем их семантические отношения. В результате, модель получает возможность манипулировать визуальными концепциями, используя возможности обработки естественного языка, что позволяет эффективно комбинировать их и создавать новые визуальные композиции. Такой подход позволяет модели понимать и воспроизводить сложные визуальные сцены, основываясь на текстовом описании.
В основе BiCo лежит архитектура Diffusion Transformer (DiT), использующая принципы диффузионных моделей для генерации видео высокого качества. DiT, как и другие диффузионные модели, работает путем постепенного добавления шума к обучающим данным до тех пор, пока они не превратятся в случайный шум, а затем обучения модели для обратного процесса — удаления шума и восстановления исходных данных. В BiCo, DiT используется для генерации видеокадров, что позволяет достичь высокой детализации и реалистичности изображения. Использование архитектуры Transformer позволяет модели эффективно обрабатывать последовательности данных и учитывать контекст при генерации каждого кадра, что критически важно для создания связного и реалистичного видео.

Оптимизация Производительности Связующего Модуля посредством Обучения
Двухэтапная стратегия инверсионного обучения повышает оптимизацию binder за счет первоначальной концентрации на высоких уровнях шума. На первом этапе, модели подвергаются воздействию данных с высоким уровнем шума, что способствует развитию устойчивости к помехам и улучшению способности к обобщению. Последующий этап обучения с использованием менее шумных данных позволяет уточнить параметры модели и повысить точность кодирования и извлечения визуальных концепций. Такой подход позволяет модели эффективно работать в сложных сценариях, где присутствуют значительные шумы и искажения, обеспечивая более стабильные и надежные результаты.
Данный подход к обучению модели обеспечивает эффективное кодирование и извлечение визуальных концепций даже в сложных ситуациях. Использование стратегии инвертированного обучения с начальным акцентом на высокий уровень шума позволяет модели развивать устойчивость к помехам и неполноте данных. Это достигается за счет того, что модель учится выделять ключевые признаки и взаимосвязи, несмотря на искажения, что повышает ее способность к обобщению и точному воспроизведению визуальной информации в различных условиях. В результате, модель демонстрирует улучшенную производительность в задачах, требующих анализа и интерпретации сложных визуальных сцен.
Согласно результатам человеческой оценки, BiCo демонстрирует превосходство над предыдущими методами в области согласованности концепций, точности следования запросам и качестве движения. В частности, общая оценка качества генераций, полученных с использованием BiCo, на 54.67% выше, чем у DualReal. Данный показатель подтверждает эффективность BiCo в создании визуально когерентных и соответствующих заданным условиям видеоматериалов, превосходящих существующие аналоги по ключевым параметрам.
Будущее Гибкого Визуального Контента: Новые Горизонты Творчества
Метод BiCo открывает новые возможности для создания визуального контента, позволяя пользователям легко комбинировать различные концепции и генерировать сложные видеоролики с минимальными усилиями. В отличие от традиционных подходов, требующих обширных настроек и ручного труда, BiCo обеспечивает гибкое объединение визуальных элементов, опираясь на инновационную систему связывания визуальных понятий с текстовыми запросами. Это позволяет пользователям быстро экспериментировать с различными идеями и создавать уникальные видеоматериалы, не обладая глубокими знаниями в области видеомонтажа или программирования. По сути, BiCo упрощает процесс визуального повествования, делая его доступным для широкого круга пользователей и открывая новые горизонты для творчества и самовыражения.
Метод BiCo, использующий обучение с единого примера, открывает новые возможности для быстрой разработки и персонализации визуального контента. В отличие от традиционных подходов, требующих обширных наборов данных для обучения, BiCo способен адаптироваться к новым визуальным концепциям, используя лишь один пример изображения. Это значительно ускоряет процесс прототипирования, позволяя пользователям оперативно экспериментировать с различными визуальными решениями и создавать уникальный контент без длительного обучения модели. Такая способность к быстрой адаптации особенно ценна в динамичных сферах, где требуется оперативная генерация визуальных материалов, отвечающих постоянно меняющимся требованиям и трендам.
Представленные в Таблице 1 количественные результаты демонстрируют заметное улучшение показателей BiCo по сравнению с базовыми методами. В частности, наблюдается существенный рост значений CLIP Score, отражающего степень соответствия сгенерированного видео текстовому описанию, и DINO Score, оценивающего сохранность визуальных концепций. Эффективно связывая визуальные элементы с текстовыми токенами, BiCo совершает важный шаг к созданию более интуитивно понятных и мощных систем генерации видео, управляемых искусственным интеллектом, открывая возможности для быстрого прототипирования и персонализации визуального контента.
Представленная работа демонстрирует элегантный подход к композиции визуальных концепций, где сложная задача разделяется на иерархические компоненты. BiCo, используя диффузионные модели и технику временного разделения, позволяет создавать высококачественные результаты, опираясь на минимальное количество входных данных. Этот метод подчеркивает важность гармоничного сочетания формы и функции, подобно тому, как Дэвид Марр однажды заметил: «Понимание — это построение моделей, предсказывающих, что произойдет». BiCo, по сути, строит модель визуального мира, предсказывая, как различные концепции могут быть объединены для создания нового контента. Такой подход подтверждает, что красота масштабируется, а беспорядок нет — простота и ясность структуры обеспечивают надежность и эффективность системы.
Куда же это всё ведёт?
Представленная работа, безусловно, демонстрирует элегантность подхода к композиции визуальных концепций. Однако, подобно искусному гобелену, где каждый узелок имеет значение, остаются нерешенные вопросы. Одношаговость метода, хотя и впечатляет, всё же требует дальнейшей проверки в условиях, когда входные данные далеки от идеала. Простота — это не всегда признак истины, а скорее — признак умения обходить сложные проблемы. Неизбежно возникает вопрос о масштабируемости: как BiCo поведет себя при композиции не двух, а десятка, сотни концепций?
Более глубокое исследование требует не только улучшения алгоритмов, но и переосмысления самого понятия «концепция». Что именно является фундаментальной единицей визуального языка? В данном контексте, временное разделение, хотя и полезно, может оказаться лишь частью более сложной системы, отражающей нелинейную природу восприятия. Следующим шагом представляется разработка моделей, способных не просто комбинировать концепции, а генерировать принципиально новые, неожиданные визуальные метафоры.
В конечном счете, ценность подобного рода исследований определяется не только технической сложностью, но и их способностью расширить границы нашего визуального мышления. Истинная элегантность заключается не в создании иллюзии совершенства, а в признании сложности и постоянном стремлении к более глубокому пониманию.
Оригинал статьи: https://arxiv.org/pdf/2512.09824.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
2025-12-12 00:09