Автор: Денис Аветисян
Исследователи предлагают эффективный метод улучшения качества и скорости генерации изображений с помощью Diffusion Transformers, используя внутренние сигналы самой модели.
![В исследовании продемонстрировано, что внутренняя навигация позволяет эффективно устранять выбросы, возникающие при использовании недостаточно обученных моделей диффузии шумоподавления, и ускорять сходимость обучения, превосходя по эффективности существующие методы, такие как REPA[yu2024representation], в экспериментах SiT-B/2.](https://arxiv.org/html/2512.24176v1/x4.png)
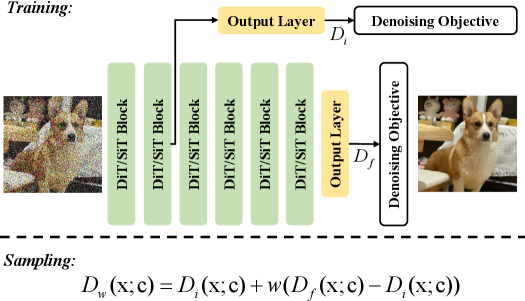
В статье представлена стратегия Internal Guidance (IG), использующая промежуточные представления Diffusion Transformers для повышения эффективности обучения и качества сгенерированных изображений.
Несмотря на впечатляющую способность диффузионных моделей захватывать сложные распределения данных, их производительность часто снижается в областях с низкой вероятностью. В данной работе, ‘Guiding a Diffusion Transformer with the Internal Dynamics of Itself’, предложен новый метод — Internal Guidance (IG) — для улучшения качества генерации и эффективности обучения диффузионных трансформеров. IG использует информацию из промежуточных слоев сети для управления процессом генерации, что позволяет получать более реалистичные и детализированные изображения. Возможно ли дальнейшее повышение качества генерации, используя внутренние представления сети для более точной навигации по пространству вероятностей?
Фундамент: Диффузионные Модели и Трансформеры — Теория, Которая Оправдывает Себя
Генеративное моделирование претерпело значительную трансформацию благодаря диффузионным моделям, демонстрирующим передовые результаты в различных областях, от создания изображений и звука до обработки текста и даже моделирования молекулярных структур. В отличие от традиционных генеративных состязательных сетей (GAN), диффузионные модели работают, постепенно добавляя шум к данным, а затем обучаясь обращать этот процесс, восстанавливая исходные данные из шума. Этот подход позволяет создавать более стабильные и реалистичные результаты, избегая многих проблем, связанных с обучением GAN, таких как коллапс моды. Способность этих моделей эффективно улавливать сложные распределения данных открывает новые возможности для творчества и научных исследований, позволяя генерировать контент, неотличимый от реального.
В последнее время наблюдается устойчивая тенденция к интеграции архитектуры Transformer в диффузионные модели, что обусловлено её способностью эффективно моделировать сложные распределения данных. Transformer, изначально разработанный для обработки последовательностей в задачах обработки естественного языка, оказался удивительно эффективным в захвате долгосрочных зависимостей и сложных взаимосвязей в различных модальностях, включая изображения и аудио. Благодаря механизму внимания, Transformer позволяет моделям концентрироваться на наиболее релевантных частях входных данных, что критически важно для генерации высококачественного и когерентного контента. В результате, диффузионные модели, использующие Transformer, демонстрируют превосходные результаты в задачах генерации, превосходя традиционные подходы и открывая новые возможности для создания реалистичных и разнообразных данных.
Несмотря на впечатляющие успехи, эффективное управление процессом генерации в диффузионных моделях остается сложной задачей. Модели способны создавать высокореалистичные изображения и другие типы данных, однако точное направление этого процесса, чтобы получить желаемый результат, требует дальнейших исследований. Существующие методы, такие как классификационное управление, зачастую не позволяют в полной мере использовать потенциал модели, приводя к непредсказуемым или нежелательным результатам. Сложность заключается в тонком балансе между сохранением разнообразия генерируемых данных и обеспечением соответствия заданным критериям, что требует разработки более совершенных алгоритмов и техник управления процессом диффузии.
Несмотря на значительные успехи, существующие методы управления процессом генерации в диффузионных моделях, такие как Classifier-Free Guidance (CFG), демонстрируют определенные ограничения в полной реализации потенциала модели. CFG, хотя и позволяет контролировать выходные данные без необходимости в дополнительной классификации, часто страдает от компромисса между качеством генерируемых образцов и степенью соответствия заданным условиям. В частности, при высоких уровнях управления, CFG может приводить к снижению разнообразия и появлению артефактов, а при низких — к недостаточно точной генерации желаемого контента. Исследования показывают, что существующие методы не всегда способны эффективно использовать всю информацию, закодированную в параметрах модели, что препятствует достижению оптимального баланса между качеством, разнообразием и точностью генерируемых данных. Таким образом, разработка более совершенных техник управления, способных полностью раскрыть потенциал диффузионных моделей, остается актуальной задачей.

Внутреннее Управление: Новый Подход к Контролю — Избавляемся от Костылей
Внутреннее управление (IG) представляет собой новую стратегию сэмплирования, использующую выходные данные промежуточных слоев в архитектуре Diffusion Transformers. Вместо традиционных методов, полагающихся на внешние классификаторы или финальные слои, IG непосредственно использует представления, сформированные на различных этапах процесса диффузии. Это позволяет более точно и детально управлять процессом генерации, используя информацию, содержащуюся в промежуточных активациях. Конкретно, IG извлекает признаки из внутренних слоев трансформатора и использует их для корректировки процесса шумоподавления, направляя генерацию к желаемому результату без необходимости привлечения внешних моделей.
Внутреннее управление (Internal Guidance, IG) обеспечивает более прямое и детализированное воздействие на процесс генерации по сравнению с традиционными методами, поскольку использует внутренние представления, формирующиеся на промежуточных слоях Diffusion Transformers. Традиционные подходы часто полагаются на сигналы, полученные из конечного результата или внешних классификаторов, что приводит к косвенному контролю и потенциальным потерям информации. IG, напротив, оперирует непосредственно с представлениями признаков, сформированными на различных стадиях обработки, что позволяет более точно и эффективно направлять процесс генерации, учитывая сложные взаимосвязи между признаками и обеспечивая более тонкую настройку выходных данных.
В отличие от традиционных методов управления генерацией, стратегия Internal Guidance (IG) не требует использования внешних классификаторов. Это упрощает конвейер генерации, исключая необходимость обучения и интеграции дополнительных моделей, что значительно снижает вычислительные затраты. Отсутствие внешних классификаторов также уменьшает сложность настройки и калибровки системы, позволяя быстрее и эффективнее получать желаемые результаты. Использование внутренних представлений Diffusion Transformers в качестве сигналов управления позволяет обойтись без внешней оценки, тем самым оптимизируя производительность и снижая общую стоимость вычислений.
Внутреннее управление (IG) улучшает качество генерируемых образцов за счет использования дополнительного контроля (Auxiliary Supervision). Этот подход заключается в применении дополнительных сигналов, полученных из промежуточных слоев сети, для уточнения направляющих векторов. В частности, Auxiliary Supervision позволяет снизить шум и повысить точность направлений, используемых для управления процессом диффузии, что приводит к генерации более четких и детализированных результатов. Использование дополнительных сигналов позволяет IG адаптироваться к различным типам данных и задачам, обеспечивая повышенную гибкость и производительность по сравнению с методами, использующими только выходные данные последнего слоя.
Архитектурные Синергии и Мощность Представлений — Как Всё Работает Вместе
Интеграция IG (Interrogative Guidance) совместима с различными архитектурами Diffusion Transformer, включая SiT (Scaled Image Transformer), DiT (Diffusion Transformer) и LightningDiT. Данная совместимость обеспечивает гибкость при реализации, позволяя использовать IG с различными моделями для генерации изображений. SiT использует масштабируемые блоки трансформаторов, DiT объединяет принципы диффузии и трансформаторов, а LightningDiT является оптимизированной версией DiT, что предоставляет разработчикам широкий выбор архитектур для интеграции с IG и адаптации к конкретным задачам и вычислительным ресурсам.
Использование методов обучения представлений (Representation Learning) в архитектурах SiT, DiT и LightningDiT позволяет создавать более эффективные и информативные представления данных. Вместо обработки исходных данных напрямую, эти модели учатся извлекать ключевые признаки и характеристики, что снижает вычислительную сложность и повышает точность. Такой подход обеспечивает более компактное и осмысленное кодирование информации, что особенно важно для задач генерации изображений, позволяя моделям быстрее обучаться и достигать лучших результатов, как демонстрируется в экспериментах с ImageNet 256×256, где модели, использующие обучение представлений, достигают более низких оценок FID при значительно меньшем количестве эпох обучения.
Автонаправление (Autoguidance) и точный контроль интервала управления (Guidance Interval) позволяют оптимизировать процесс дискретизации в диффузионных моделях. Автонаправление динамически корректирует силу управляющего сигнала в процессе генерации, адаптируясь к текущему состоянию изображения и повышая его соответствие заданным условиям. Контроль интервала управления позволяет определить, на каких этапах генерации необходимо применять наиболее сильное управление, что влияет на качество и скорость сходимости процесса. Эти методы совместно обеспечивают более эффективное использование информации, содержащейся в управляющем сигнале, и позволяют достичь лучших результатов при генерации изображений.
Экспериментальные результаты демонстрируют превосходство моделей, улучшенных с использованием IG. На датасете ImageNet 256×256 с архитектурой LightningDiT-XL/1 достигнут показатель FID (Fidelity and Inception Distance) в 1.19, что является state-of-the-art результатом. При использовании SiT-XL/2, IG достигает FID 5.31 уже на 80 эпохе обучения, значительно превосходя стандартную SiT-XL, которой для достижения сопоставимого результата требуется 1400 эпох. Кроме того, при 800 эпохах обучения с SiT-XL/2 показатель FID составляет 1.75, а с LightningDiT-XL/1 на 60 эпохе — 2.42, который улучшается до 1.34 при 680 эпохах.

Устранение Проблем с Градиентом и Перспективы — Куда Мы Двигаемся?
Исследования показали, что метод Internal Guidance (IG) эффективно решает проблему затухания градиентов, возникающую при обучении глубоких Diffusion Transformers. Затухание градиентов, особенно в глубоких слоях нейронных сетей, затрудняет процесс обучения, препятствуя эффективному обновлению весов. IG, используя внутренние представления данных, обеспечивает более сильный и устойчивый сигнал градиента, позволяя сети обучаться более эффективно и быстро сходиться к оптимальным параметрам. Это, в свою очередь, открывает возможности для создания более сложных и мощных генеративных моделей, способных решать задачи, ранее недоступные из-за ограничений, связанных с нестабильностью обучения.
Исследование показывает, что механизм Internal Guidance (IG) усиливает градиентные сигналы, особенно в глубоких слоях диффузионных трансформаторов. Используя внутренние представления модели, IG позволяет более эффективно передавать информацию об ошибке от выходного слоя к более ранним слоям, что решает проблему затухания градиента. Это достигается за счет того, что IG формирует более четкие и сильные градиенты, облегчая процесс обучения и позволяя модели быстрее сходиться к оптимальным параметрам. Таким образом, IG способствует повышению стабильности модели и улучшению качества генерируемых данных, открывая новые возможности для решения сложных задач генерации.
Улучшенная стабильность и ускоренная сходимость обучения, наблюдаемые при использовании предложенного подхода, являются прямым следствием усиления градиентных сигналов в глубоких слоях нейронной сети. Исследования показали, что более сильные градиенты позволяют модели более эффективно корректировать свои параметры на каждой итерации, что приводит к более плавному процессу обучения и снижению риска расхождения. Это, в свою очередь, позволяет сократить время, необходимое для достижения оптимальных результатов, и повысить надежность модели в целом, особенно при работе со сложными архитектурами, такими как Diffusion Transformers. Полученные данные свидетельствуют о значительном прогрессе в решении проблемы затухания градиента и открывают новые возможности для создания более мощных и эффективных генеративных моделей.
Перспективные исследования направлены на расширение области применения IG в задачах генерации, характеризующихся повышенной сложностью и разнообразием. Особый интерес представляет изучение возможности интеграции IG в модели, работающие с мультимодальными данными, такими как одновременная обработка изображений, текста и звука. Предполагается, что использование IG позволит создавать более реалистичные и детализированные генеративные модели, способные решать задачи, ранее недоступные из-за проблем с обучением глубоких сетей. В частности, планируется исследовать применение IG в областях, требующих генерации сложных сцен, высококачественной графики и реалистичного синтеза речи, что открывает новые возможности для развития искусственного интеллекта и креативных технологий.

Исследование демонстрирует, как внутреннее руководство (Internal Guidance) позволяет Diffusion Transformer’ам более эффективно использовать промежуточные представления, ускоряя процесс обучения и повышая качество генерируемых изображений. Это закономерно: каждая «революционная» технология завтра станет техдолгом. Авторы, по сути, заставляют модель использовать собственные внутренние сигналы для самокоррекции, что напоминает попытку залатать дыры в коде, которые неизбежно появляются со временем. Как метко заметил Дэвид Марр: «Интеллект — это не волшебство, а просто способ организации информации». В данном случае, грамотная организация промежуточных представлений позволяет модели обходить сложные этапы, повышая эффективность. CI/CD конвейер, конечно, не спасёт от новых ошибок, но хоть немного замедлит энтропию.
Куда Ведет Этот Путь?
Предложенная в данной работе стратегия «внутренней наводки» (Internal Guidance) выглядит как очередная попытка заставить диффузионные модели работать быстрее и качественнее. Нельзя сказать, что это нежелательно, но история учит: каждая «революция» в области генеративных моделей неминуемо превращается в технический долг. Ускорение обучения — это хорошо, пока не потребуется масштабировать решение на данные, которые не укладываются в аккуратные бенчмарки. Похоже, что в конечном итоге, проблема сводится не к архитектуре, а к данным, и этот вопрос, как всегда, остаётся в тени.
Очевидно, что использование промежуточных представлений трансформера может дать прирост в качестве генерации, но это лишь временное облегчение. Вместо того, чтобы бороться с симптомами, следует задуматься о природе самого процесса диффузии. Все эти ухищрения с «наводкой» напоминают попытку починить прохудившуюся лодку, пока она тонет. В конечном счёте, потребуется принципиально новый подход, или же мы продолжим бесконечно оптимизировать уже существующие решения, как будто багтрекер — это дневник боли, который можно переписать.
Вероятно, дальнейшие исследования будут направлены на адаптацию данной стратегии к другим типам данных и моделям. Но не стоит забывать, что в конечном итоге, «мы не деплоим — мы отпускаем» эти модели в мир, полный неожиданностей. И тогда все эти ухищрения с «внутренней наводкой» окажутся лишь незначительным улучшением в хаотичном процессе генерации.
Оригинал статьи: https://arxiv.org/pdf/2512.24176.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Квантовые нейросети на службе нефтегазовых месторождений
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Квантовая криптография: от теории к практике
- Робот, который видит, понимает и действует: новая эра общего назначения
- Лунный гелий-3: Охлаждение квантового будущего
- Квантовые сети для моделирования молекул: новый подход
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые прорывы: Хорошее, плохое и смешное
2026-01-01 14:57