Автор: Денис Аветисян
В статье представлена инновационная архитектура, позволяющая существенно расширить возможности больших языковых моделей при обработке длинных текстов и сложных задач.

Рекурсивные языковые модели (RLM) используют принцип взаимодействия с внешней средой для масштабирования эффективной длины входных и выходных последовательностей.
Несмотря на впечатляющие возможности больших языковых моделей (LLM), обработка длинных последовательностей текста остается сложной задачей. В работе под названием ‘Recursive Language Models’ предложена новая стратегия, рассматривающая длинные запросы как внешнюю среду, с которой модель может взаимодействовать, рекурсивно анализируя и обрабатывая отдельные фрагменты. Показано, что данный подход позволяет значительно расширить контекстное окно и превзойти существующие методы обработки длинных текстов по качеству и стоимости. Какие перспективы открывает рекурсивный подход для создания LLM, способных эффективно работать с произвольно длинными входными данными?
Предел Контекста: Почему Модели «Забывают» Длинные Тексты
Современные языковые модели, несмотря на свою впечатляющую способность к обработке текста, сталкиваются с серьезными ограничениями при работе с очень длинными последовательностями. Это связано с так называемым “окном контекста” — фиксированным объемом информации, который модель может учитывать одновременно. Превышение этого лимита приводит к потере важной информации из начала последовательности, что существенно снижает качество ответов и затрудняет выполнение задач, требующих понимания всей картины. Фактически, модель “забывает” начало длинного текста, концентрируясь лишь на последних фрагментах, что делает ее неэффективной для анализа объемных документов, длинных диалогов или сложных повествований. Эта проблема становится особенно актуальной в задачах, требующих глубокого понимания и логических выводов на основе всего доступного текста.
Ограничение на длину контекста создает серьезную проблему, известную как «долгосрочная проблема», существенно снижающую эффективность языковых моделей при решении задач, требующих всестороннего анализа обширных текстовых данных. Когда модели сталкиваются с текстами, превышающими их контекстное окно, способность к пониманию и логическим выводам заметно ухудшается. Это особенно критично в задачах, связанных с анализом юридических документов, научных статей или больших литературных произведений, где важна целостная картина и способность улавливать взаимосвязи между отдаленными частями текста. Неспособность учитывать всю доступную информацию приводит к неточностям, упущениям и, как следствие, к снижению качества результатов, что делает решение «долгосрочной проблемы» ключевым направлением в развитии современных языковых технологий.
Обработка длинных последовательностей текста становится все более затратной по мере увеличения их длины, что связано с так называемой стоимостью токенов — вычислительными ресурсами, необходимыми для анализа каждого элемента последовательности. Традиционные языковые модели демонстрируют заметное снижение эффективности при увеличении длины контекста, что ограничивает их применение в задачах, требующих глубокого понимания больших объемов информации. В отличие от них, рекурсивные языковые модели (RLM) способны сохранять стабильную производительность даже при работе с очень длинными текстами, предлагая перспективное решение для преодоления этой проблемы и повышения эффективности обработки информации.

Сжатие Контекста: Попытки Уменьшить «Объем» Информации
Для решения проблемы обработки длинных контекстов (Long-Context Problem) необходимы методы компрессии контекста, направленные на сокращение входной последовательности без потери существенной информации. Эти методы включают в себя различные стратегии, такие как выбор наиболее релевантных фрагментов текста, абстрагирование информации путем обобщения или использование алгоритмов понижения размерности. Эффективная компрессия позволяет моделям обрабатывать документы, превышающие размер их контекстного окна, сохраняя при этом возможность доступа к ключевым фактам и взаимосвязям, необходимым для выполнения поставленной задачи. Выбор оптимального метода компрессии зависит от конкретного типа данных и требований к точности и скорости обработки.
Итеративное суммирование представляет собой перспективный подход к сжатию контекста, заключающийся в последовательном сокращении объема длинных документов с сохранением ключевой информации. Этот метод предполагает многократное применение алгоритмов суммирования, каждый раз уменьшая размер входного текста, при этом стараясь выделить и сохранить наиболее значимые фрагменты. Процесс может быть выполнен как автоматически, с использованием моделей обработки естественного языка, так и с привлечением человека для контроля качества и обеспечения релевантности полученных сокращенных версий. Результатом является более компактный документ, который сохраняет основные идеи и позволяет модели эффективно обрабатывать длинные последовательности данных.
Метод итеративного суммирования эффективно расширяет возможности контекстного окна языковых моделей, позволяя им обрабатывать последовательности большей длины, чем ранее возможно. Однако, по сравнению с подходом, представленным в данной работе, итеративное суммирование часто демонстрирует меньшую эффективность в сохранении ключевой информации и поддержании когерентности при работе с очень длинными текстами. Это связано с неизбежной потерей деталей на каждом этапе суммирования, что может негативно сказаться на точности и полноте ответов модели.
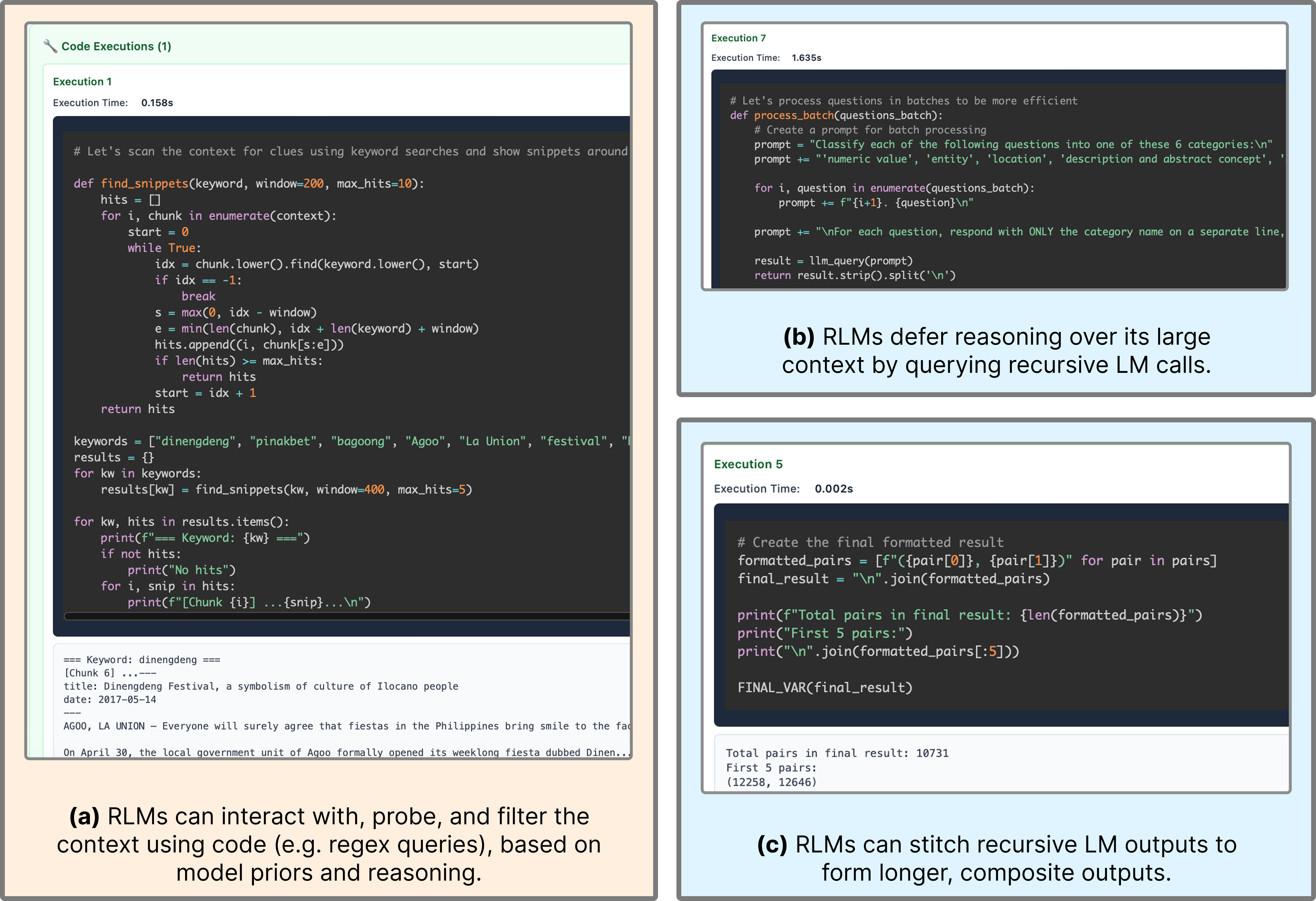
Поиск и Рассуждения: Усиление Понимания Длинного Контекста
Эффективное понимание длинного контекста требует не только компрессии данных, но и надежного поиска релевантной информации. Методы, такие как BM25, играют ключевую роль в идентификации наиболее значимых фрагментов текста. BM25 — это алгоритм ранжирования, основанный на вероятностной модели, который оценивает релевантность документа запросу, учитывая частоту встречаемости терминов в документе и в коллекции, а также длину документа. Использование BM25 позволяет эффективно отфильтровывать нерелевантную информацию, сосредотачиваясь на фрагментах, содержащих ключевые данные для решения поставленной задачи. Таким образом, BM25 является важным компонентом систем обработки длинного контекста, обеспечивая точный и быстрый поиск необходимой информации.
Метод ReAct (Reason + Act) представляет собой подход к решению сложных задач, который сочетает в себе этапы рассуждения и действия. Модель генерирует цепочку мыслей (Thought), которая позволяет ей анализировать полученную информацию, а затем выполняет конкретное действие (Action) на основе этого анализа. Полученные наблюдения (Observation) после действия используются для корректировки дальнейших рассуждений и действий, что позволяет модели итеративно приближаться к решению задачи. Использование ReAct особенно эффективно при работе с извлечённой из внешних источников информацией, поскольку позволяет модели не просто получать данные, но и активно использовать их для достижения цели.
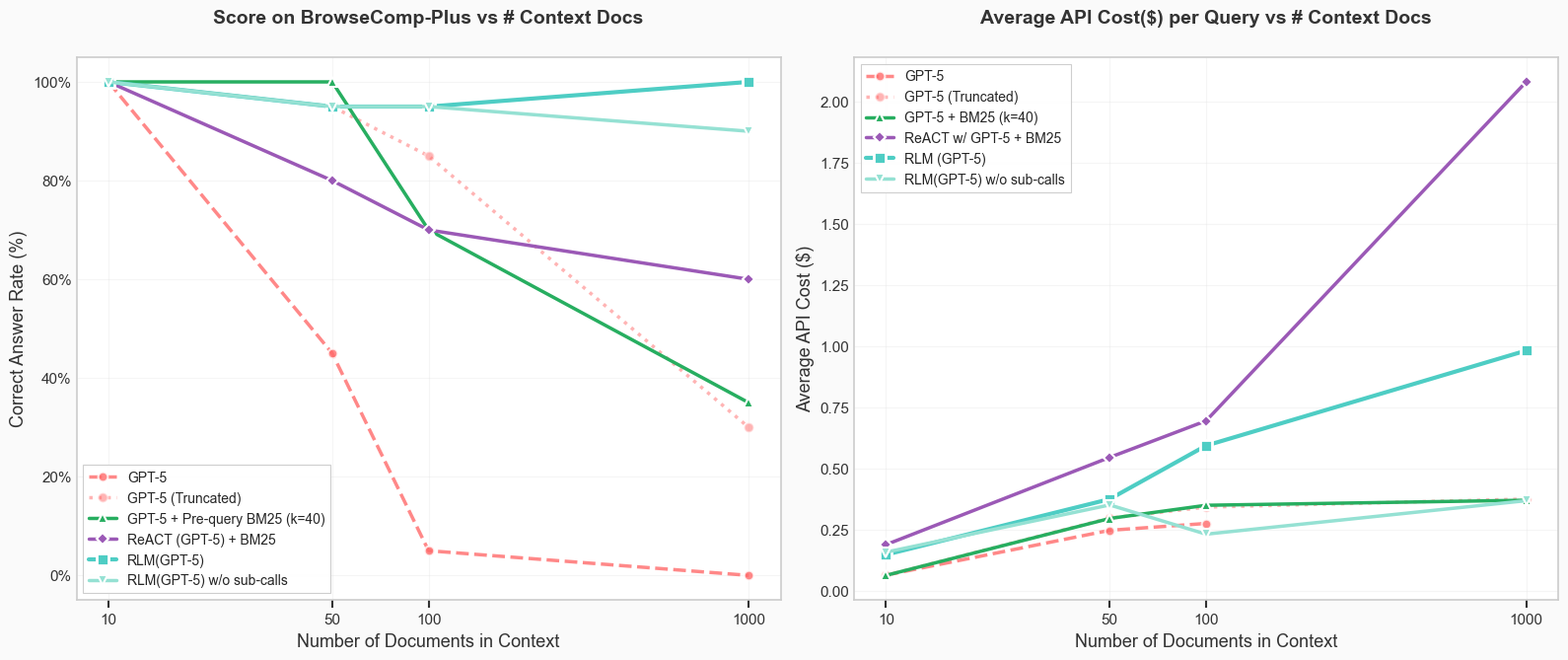
Наборы данных, такие как BrowseComp+ и OOLONG, являются ключевыми эталонами для строгой оценки способности моделей к рассуждениям на основе длинных контекстов и определению релевантности извлеченной информации. Традиционно, производительность моделей на этих бенчмарках снижается с увеличением размера контекста, однако предложенный в данной работе подход демонстрирует сохранение идеальной точности даже при обработке контекста, состоящего из 1000 документов.
Рекурсивные Языковые Модели: Новый Подход к Работе с Длинным Контекстом
Рекурсивные языковые модели (RLM) представляют собой новый подход к масштабированию эффективной длины входных и выходных последовательностей в языковых моделях. В отличие от традиционных моделей, которые ограничены фиксированным контекстным окном, RLM используют рекурсивную структуру для обработки документов, превышающих эти ограничения. Данный подход позволяет модели последовательно обрабатывать информацию, разделяя большие документы на части и рекурсивно применяя языковую модель к этим частям, сохраняя при этом информацию о контексте. Это обеспечивает эффективное расширение контекстного окна без значительного увеличения вычислительных затрат, что особенно важно для задач, требующих анализа больших объемов текста, таких как обработка длинных документов или веб-страниц.
В основе рекурсивных языковых моделей (RLM) лежат предварительно обученные модели, такие как GPT-5 и Qwen3-Coder-480B-A35B. Использование этих моделей в качестве фундамента позволяет RLM эффективно обрабатывать длинные контексты, демонстрируя значительное улучшение производительности по сравнению с традиционными подходами. Предварительное обучение этих моделей на обширных корпусах данных обеспечивает наличие необходимых знаний и лингвистических навыков для успешной работы с большими объемами информации, что критически важно для задач, требующих анализа и синтеза данных из длинных текстов.
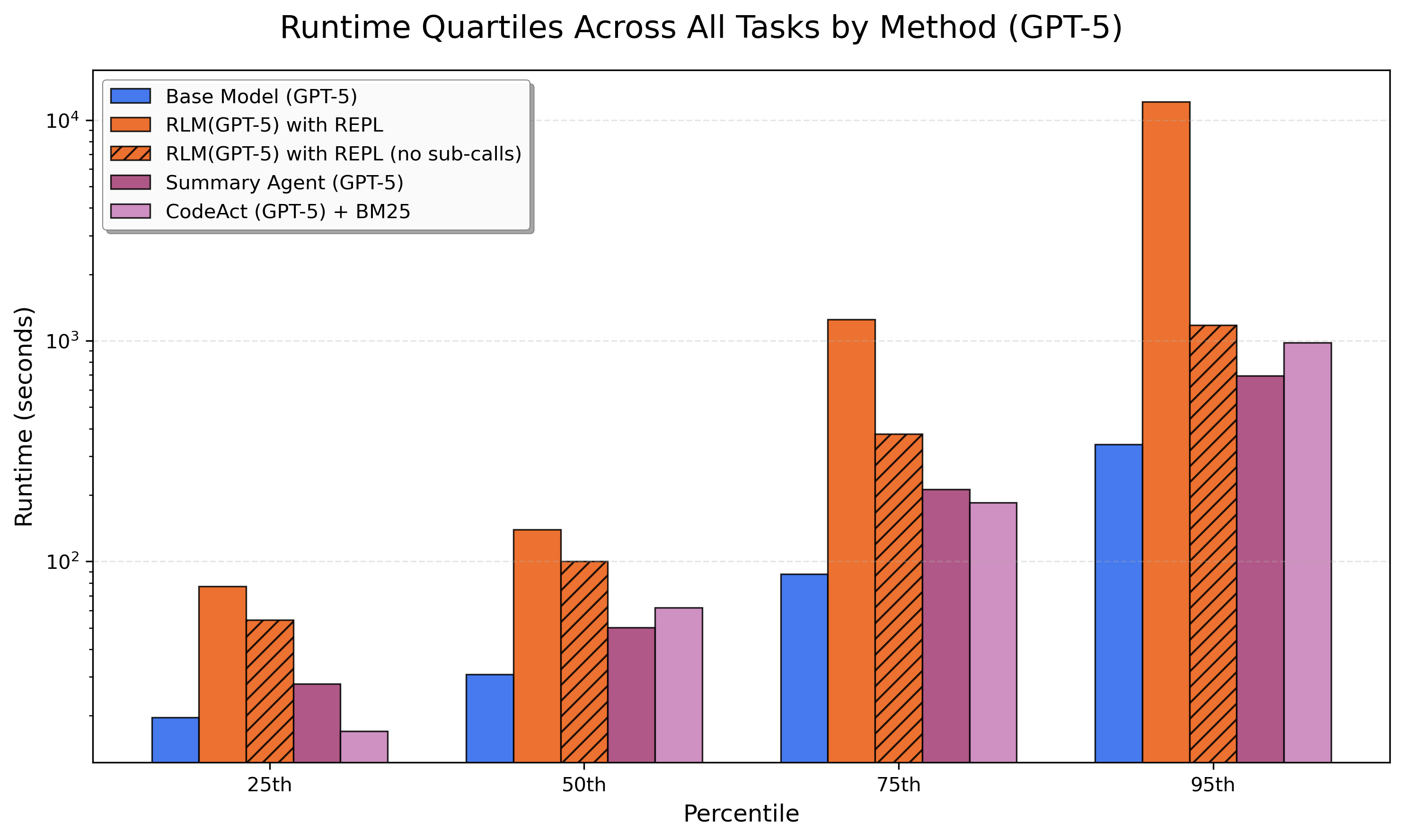
При тестировании на наборах данных `OOLONG-Pairs` и `BrowseComp+` рекурсивные языковые модели (RLM) демонстрируют 100%-ную точность обработки информации при масштабе в 1000 документов, в то время как производительность других моделей снижается. Кроме того, RLM представляется более экономичным решением для задач обработки длинных контекстов по сравнению с использованием GPT-5 с неограниченным окном контекста, что позволяет снизить вычислительные затраты.
Наблюдая за увлечением рекурсивными языковыми моделями, можно вспомнить слова Джона Маккарти: «Всякая программа со временем становится настолько сложной, что ошибки в ней неизбежны». Идея обработки промпта как внешней среды, с которой LLM взаимодействует, безусловно, элегантна. Однако, как показывает опыт миграций, любое усложнение системы рано или поздно превращается в технический долг. В контексте увеличения размера контекстного окна, заявленного в статье, неизбежно возникнут новые баги, требующие исправления. И, вероятно, когда-нибудь кто-нибудь скажет, что если баг воспроизводится — значит, у нас стабильная система. Эффективность Recursive Language Models на длинных контекстах — это хорошо, но стоит помнить, что документация к этим моделям — это лишь форма коллективного самообмана.
Что дальше?
Представленный подход к рекурсивным языковым моделям, безусловно, элегантен. Идея взаимодействия с промптом как с внешней средой — шаг к преодолению ограничений контекстного окна, которые неизбежно встают на пути масштабирования больших языковых моделей. Однако, не стоит забывать, что каждая «революция» — это лишь отсрочка технического долга. Продакшен всегда найдёт способ сломать красивую теорию, и вопрос не в том, упадёт ли система, а когда.
Основная проблема остаётся нерешённой: стоимость вычислений. Рекурсивные вызовы, уплотнение контекста, извлечение информации — всё это требует ресурсов, и пока сложно представить, что подобный подход станет действительно экономически эффективным для задач, требующих обработки огромных объёмов данных. Любая абстракция умирает от продакшена, но умирает красиво, демонстрируя новые способы оптимизации, которые, в конечном итоге, всё равно будут преодолены новыми ограничениями.
Вполне вероятно, что будущее за гибридными подходами, сочетающими рекурсивные модели с более традиционными методами извлечения и обработки информации. Всё, что можно задеплоить — однажды упадёт, и задача исследователей — сделать этот момент как можно более отдалённым, одновременно создавая инструменты для быстрой диагностики и восстановления после неизбежных сбоев.
Оригинал статьи: https://arxiv.org/pdf/2512.24601.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Метаболический профиль СДВГ: новый взгляд на диагностику
- Квантовая криптография: от теории к практике
- Робот, который видит, понимает и действует: новая эра общего назначения
2026-01-02 12:49